RAG Development: A How-To for a Security Chatbot
September 20, 2024
RAG Development: What's involved in building a RAG based Security Chatbot for your company?
Background
At Credal, we see huge demand from Enterprises wanting to build Retrieval Augmented Generation (“RAG”) applications on their data. "RAG" applications are a Generative Artificial Intelligence (Gen AI) system where a user asks a question to an AI or Large Language Model (LLM) like OpenAI's ChatGPT or Anthropic's Claude, but before the question is sent to the LLM, relevant context to help the AI answer that question is ‘retrieved’ from some internal system, and provided to the LLM alongside the user’s question to help the LLM answer correctly.
A really common RAG implementation we see at B2B SaaS companies is a security chatbot: every B2B SaaS company eventually reaches a certain scale where their customers are big enough that they have a lot of security questions before buying your product. These security concerns can be range from straightforward: (“Do you have SOC 2 Type 2 certification”) to ones that will may require more specific security expertise (“Can you provide a list of egress IPs that our Kubernetes pods will have to communicate with in order to integrate with your application").
A sales person typically can’t answer these harder questions themselves, and even the security team may have to look up the right results to certain questions themselves. With infosec teams stretched thin, this can slow down sales processes, delaying revenue or in the worst case actually causing lost deals.
But most companies already have a bank of former security questions and their answers, as well as a lot of security documentation in knowledge repositories comprised of prior pen tests, policy documents, previous audits and more. And the vast majority of questions can often be answered with a basic understanding of security and access to these knowledge bases.
Enter RAG:
This is exactly where “RAG” is useful. When one of these questions come in our system should: 1. ‘Retrieve’ the most relevant part of the documentation to answer the question
2. “Augment” the user’s question with the retrieved context, and send question and context to an LLM
3. Have the LLM ‘Generate’ a response using its specific knowledge of security, and the available documentation
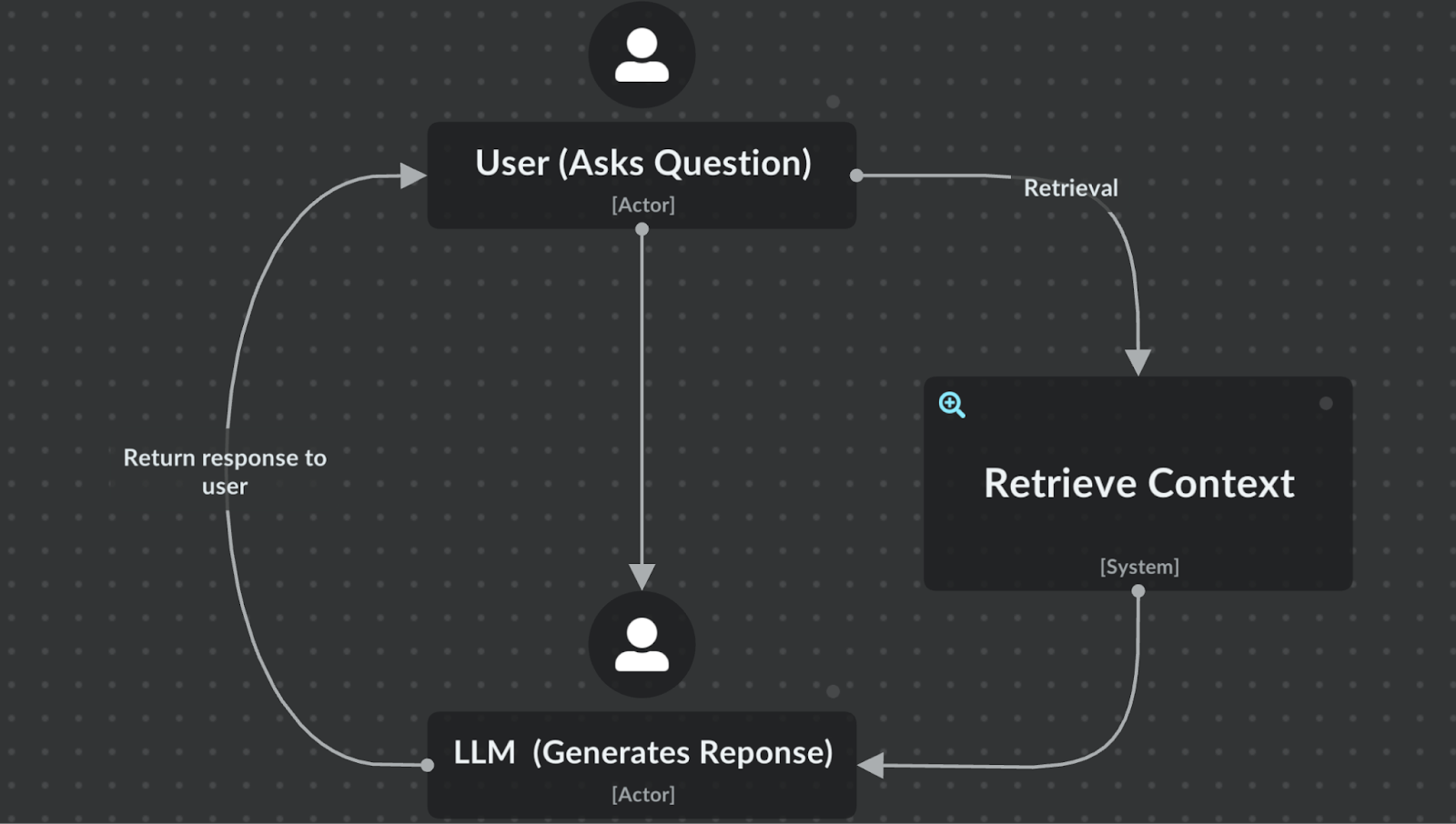
You can think of this diagram as the most naive (and vaguely defined) form of a RAG system. But what’s really involved in creating even a simple RAG tool that actually works? Building this simple RAG system can start out seeming so simple, but engineering a production worthy RAG system is often a lot trickier than it seems at first glance. It turns out, RAG Development is of course just software development, and anyone can do it, so here's a quick peek into what's actually involved:
RAG Development: ‘Retrieval’
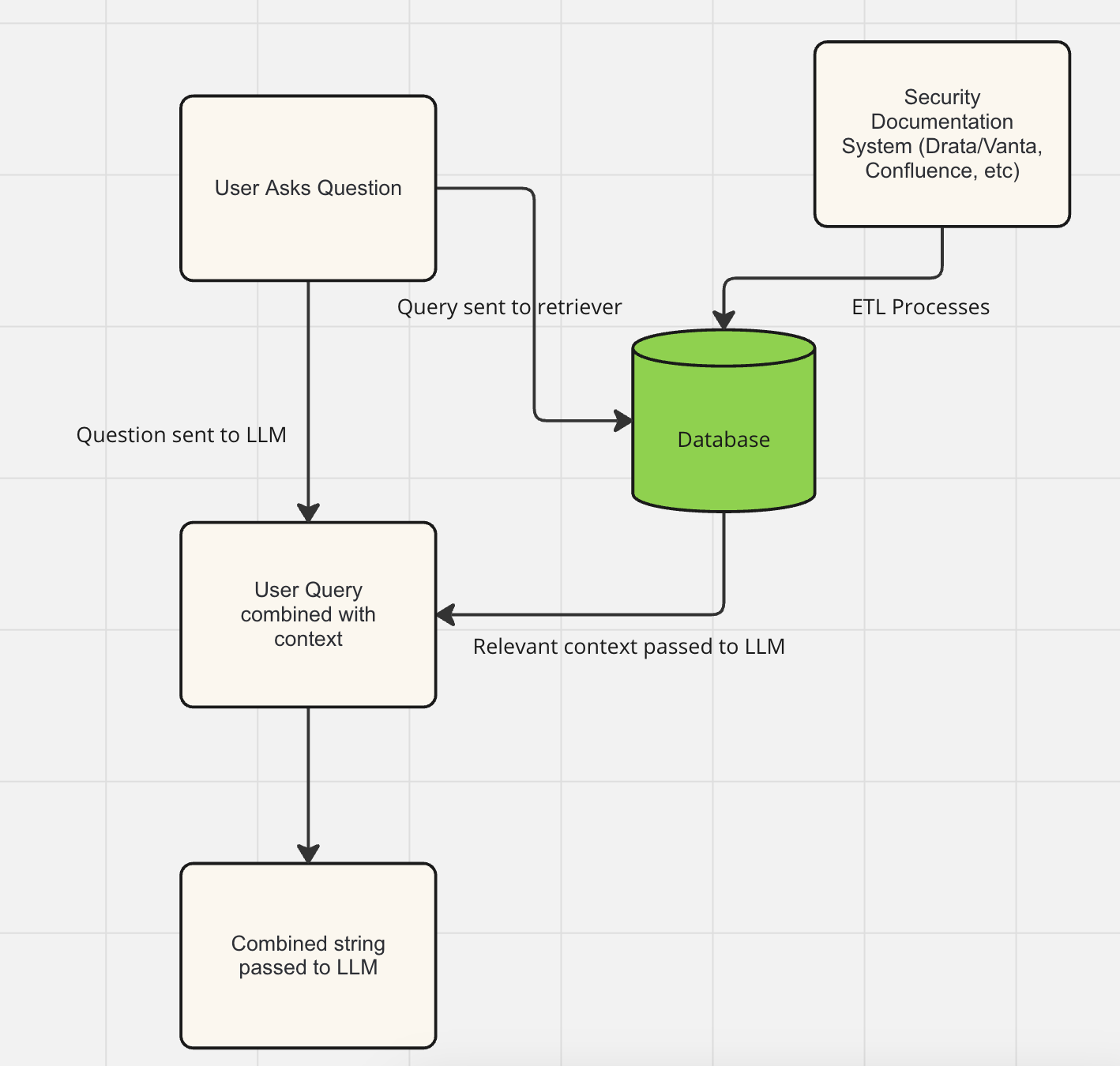
In order to be able to ‘retrieve’ the relevant context for a particular question from the security documentation, we need to do a search when the user query comes in across all the data we have for the relevant information that will help the LLM answer the user's question. That means that we need to keep a searchable index of the documentation, or else we have to interact with the APIs of the service that stores that documentation when the user's question comes in.
Retrieval: Federated vs Centralized Search?
Security docs are often stores in a variety of different places: companies using Vanta or Drata may have copies of policies in there, we also commonly see Confluence Spaces used to store certain key documents and information, and certain documents may even be access controlled to a tight group of people (for example Pen Testing results may not be available to everyone, whereas the Data Protection policy almost certainly is).
Businesses have two choices for how to proceed: 1. Ingest the data from the relevant knowledge sources into a system where it can be searched
2. Use the APIs of the service provider who stores the docs to search for the relevant context in the knowledge sources at the point of the user’s queries "Federated" search.
Although in theory there may be some benefit to the 'federated' approach, we’ve seen hardly any businesses try to build their RAG application this way. Most have opted against it because the tools built to support the creation of these documents and policies are not necessarily built to have fantastic, performant, intuitive or even well documented search. As a result, its quicker to build a RAG pipeline where we ETL (Extract, Transform, Load) the data out of these knowledge bases into a specialist data store and perform the search in that data store. In the end the result is not just quicker, but better for users as well, since this approach gives us more control over the speed at which search results return and more control over the quality of the search.
Simple RAG Pipeline:
Retrieval: Embeddings
The problem with this naive implementation of a Gen AI system is that it still doesn’t reliably provide a very good experience for the end user. With end user questions coming in as natural language, it can be super hard to to find the relevant context needed to answer the question.
Suppose a user asks:“Am I allowed to use my personal mac as my work machine at Credal?”
And suppose we have the security documentation that says:
“Employees are allowed to BYOD (‘bring your own device’) if preferred, so long as the Infosec team approves it and the appropriate controls are in place on the employee’s computer.” (this isn’t actually our policy at Credal, just an example policy).
If you just search for the keywords from the question in the security documentation, you won’t get a hit on that sentence. None of the keywords from the question are present in the most important part of the text. Even with a more sophisticated "full text search", you still may not get this result back.
So instead, most Enterprise RAG systems use a tool called embedding: it uses an LLMs ability to translate a sentence or block of text into a “Vector” (jargon for a long list of numbers that a computer can use to analyze and understand the meaning of text. If you’re interested in learning more about this, read the first section of this guide which contains a primer on information retrieval in the generative AI context, and vectors in particular: https://www.credal.ai/ai-security-guides/managing-permissions-for-vector-embeddings ).
By “embedding” both the question from the user, and the underlying documentation, we can search in the documentation for sections that have similar meaning to the user's question, not just similar keywords.
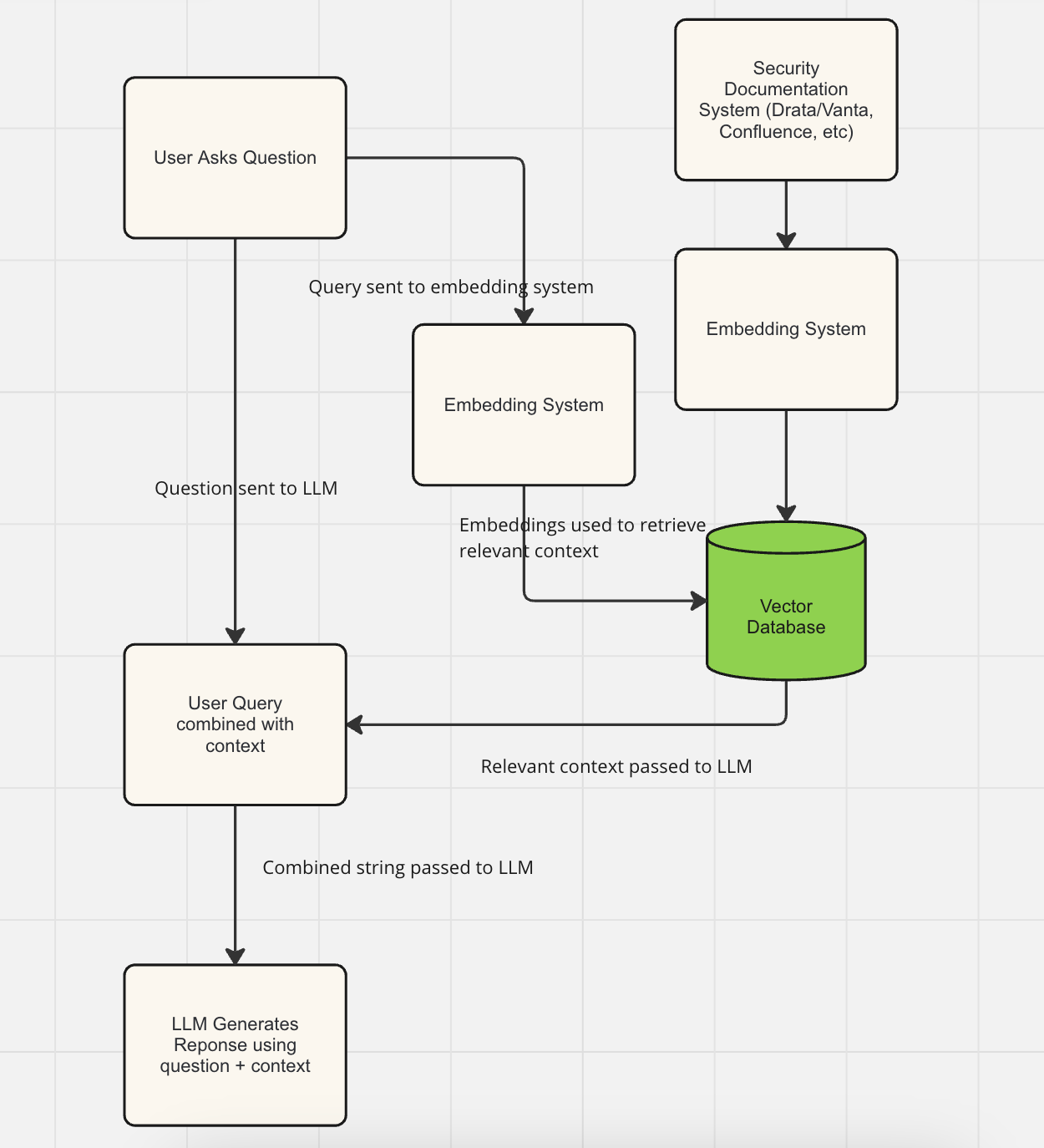
Getting the embeddings process right is a little trickier than it seems. Actually translating the text into an embedding (the list of numbers that capture the text’s meaning) is typically done by another AI model, not the LLM, but the AI labs who develop LLMs have typically also developed their own embeddings model as well. With OpenAI being so dominant in people’s minds, their embedding model tends to be the default pick of most developers.
But their embedding models barely make it into the top 10 by most impartial rankings, including the HuggingFace Leaderboard which has become the industry’s gold standard of evaluation for these types of models.
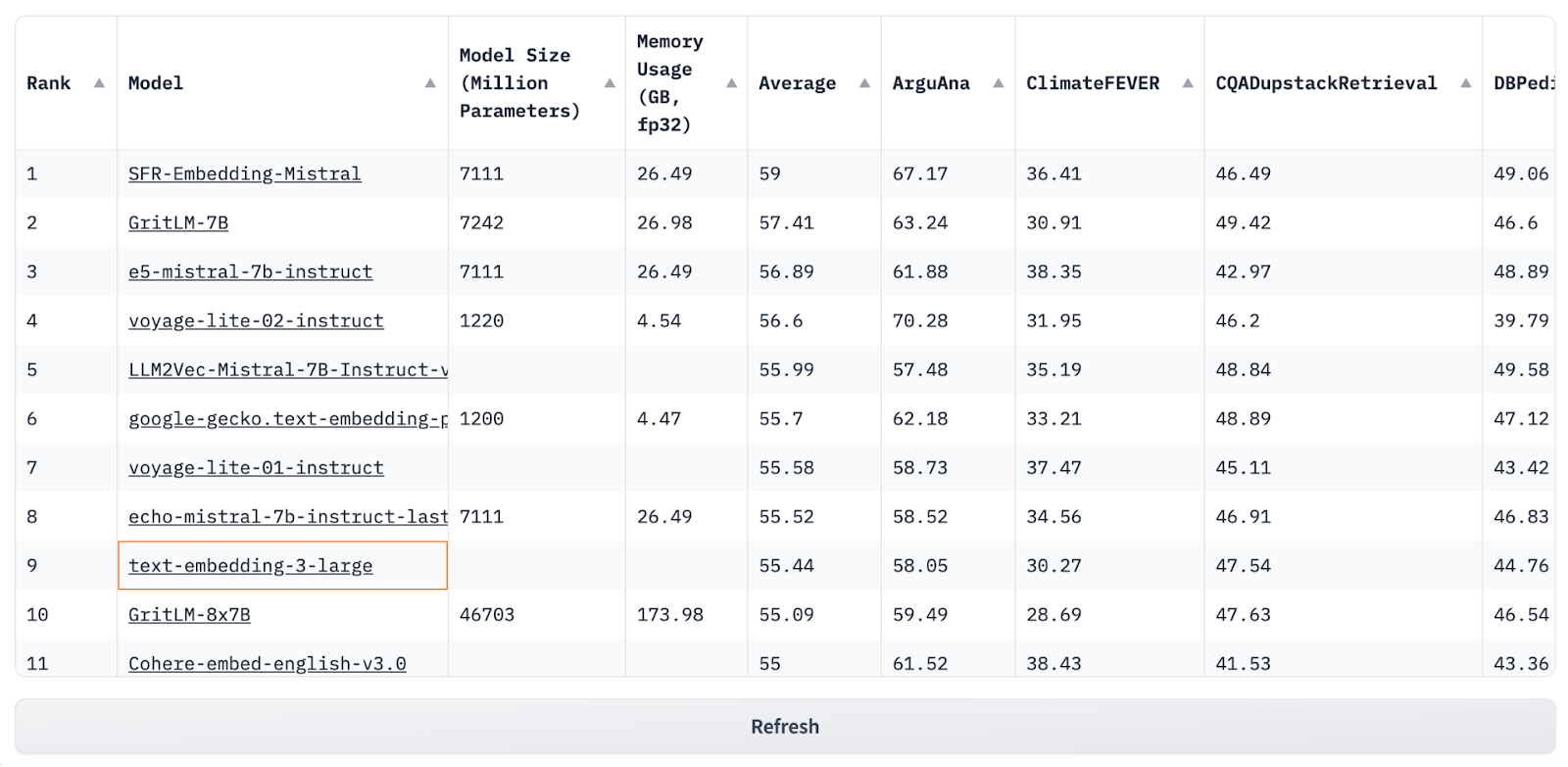
Moreover, the costs of using these different models can vary a lot, especially the 'vectors' produced by each model can vary tremendously in length (the jargon word for the length of this list is 'dimensions').
The biggest models today produce ‘vectors’ with 4096 dimensions, whereas smaller embeddings models might have just a few hundred. That can represent an order of magnitude difference in cost, and since all of this data typically has to be not just stored but indexed so it can queried very fast, these costs can add up really fast. We have one customer, uploading documents constituting around 20 million vectors to Credal (in the context of RAG scale, its big but not that bigger). Just the storage costs for the embeddings produced by OpenAI's models are over $6000 per month (not including the amount OpenAI charges you to use their model). So as you can see, your choice of model can have huge real-world cost implications. Developer’s will have to choose whether to go the easy route - just use the black-box OpenAI API, or the hard route - pick and implement the best embedding model for your usecase.
For the usecase we’re discussing here today, the security chatbot at Credal, with a RAG scale that's relatively small since there isn't much documentation to embed, using OpenAI is probably totally fine. But we do still have to choose a vector database.
Retrieval: Vector databases
Amongst the vector databases, the most popular offering today we see in the market is Pinecone, but they have no on-premise offering at all, and are still a young company. That means that you'd need to be able to trust them with your data. Other open source options include Milvus, Weaviate and QDrant, as well as PGVector. Enterprises looking for more mature businesses to partner with may prefer to work with MongoDB, who’s Atlas product was relatively late to the Vector database game but which clearly has the advantages of sitting on top of MongoDB’s tremendous distributional advantages and with a lot of focus from Mongo’s 5,000 person strong organization. It depends a little on your needs and on the 'rag scale' that your. dealing with, but in short, there are a lot of vector databases to choose from.
We now have our most basic RAG system working, but we tend to find that, when designed in this very naive way, even the most simple RAG applications such as this simple chatbot, is actually not going to perform especially well.
In particular, the weakest part of a RAG application designed this way is typically the retrieval part, since fetching the relevant chunks from the context the LLM should use to answer the question by just comparing how semantically similar the context is to the question is not quite right - really what we care about is how helpful and relevant is the context to answering the question.
Retrieval: Optimizing the Retrieval Process
In general, there are hundreds of different techniques that can be used to optimize retrieval in RAG systems, but I want to focus on a very simple security chatbot here, which realistically is not going to justify the effort of a dedicated research team.
Instead, what most companies do is just try to pick of the low hanging fruit, which typically means:
1. User Query rewriting
2. Hybrid Search
3. Reranking4. Reducing the number of duplicates / near duplicates
Query Rewriting
User Query rewriting is just taking the user’s original query, and then essentially rewriting it in a way that increases the probability that the search returns the relevant chunks of context needed to answer the user's question. For example if a user asks “What did our SOC 2 report from last year say about encryption”, when performing the search, “last year” may not be systematically similar to "2023", ‘our’ may not be semantically similar to "Credal" etc. Instead, we might choose to rewrite the original query as “2023 Credal SOC 2 report - Encryption” - and just search for the data relevant to that. Sometimes traditional natural language processing techniques are used for this rewriting, sometimes an LLM call is used instead.
Hybrid Search
Hybrid search is a common technique that combines (or “hybridizes”) the best of embeddings based semantic search and traditional keyword search. One of the tricky parts here is that the Vector databases do not all have equally good implementations of hybrid search, so if you picked Pinecone, then you've got more of a battle on your hands implementing high quality hybrid search, whereas some of the other players like Weaviate, ElasticSearch, PGVector and MongoDB might support it better.
Reranking
Reranking is a technique used after an initial search is performed, which effectively asks a mode to go through the search results as ranked by our similarity ranker, and ‘rerank’ them according to not just how similar they are to the question but in how useful they are in answering the question.
Deduplication
Finally, depending on the nature of the datasources you’re feeding into your chatbot, you may find a large number of duplicates, or near duplicates sneaking into your context. Including roughly the same context 6 times, instead of including 6 different pieces of context, reduces your chances of the most relevant or important context showing up in the content you end up showing to the LLM, so you may want to reduce the number of duplicates or near duplicates in your response.
Typical Prototype RAG pipeline:
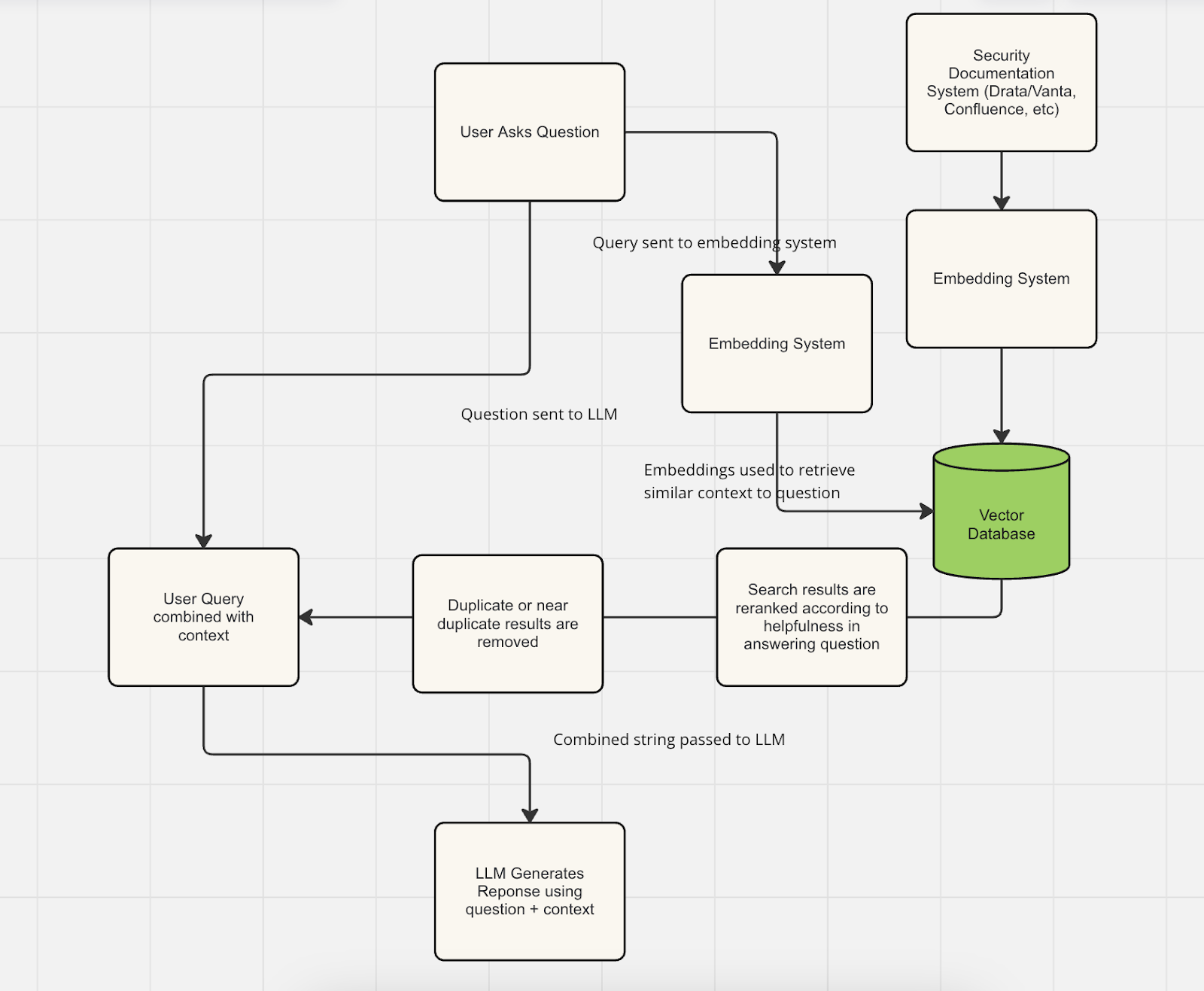
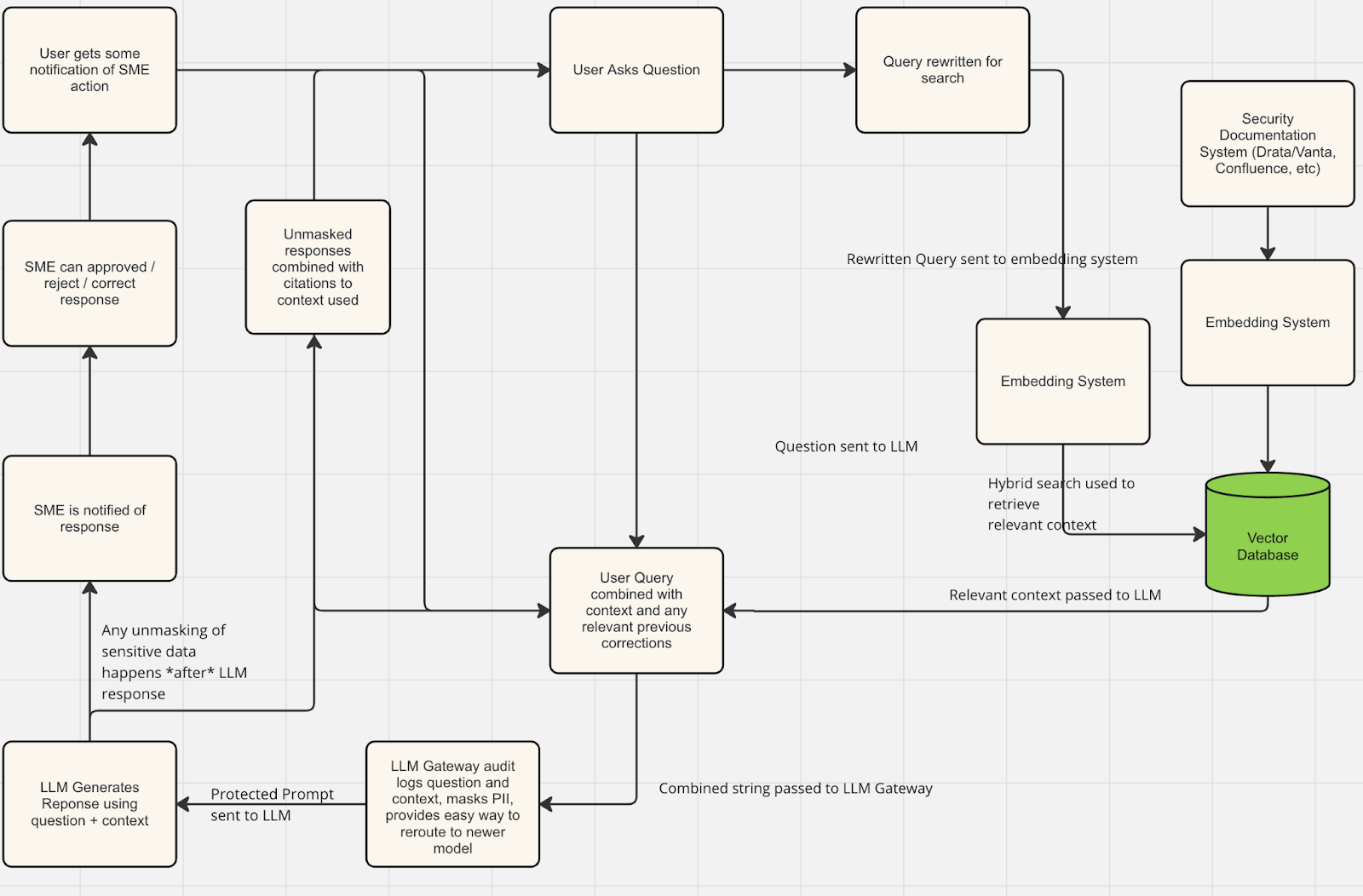
RAG Development Step 2: Getting Ready For Production We now have a security chatbot that probably works reasonably well in getting the right answer to a lot of questions, even though the right information obviously can't be in ChatGPT's training data. But to roll this out in production, we still have a couple concerns, including managing the correctness of the system and mitigating systems, securing the overall system so that sensitive data including prompts have the right technical and legal protections that prevent them making it into AI models' training data. Finally, if our external knowledge base like Confluence, JIRA, etc has permissions associated with it, we almost certainly want to make sure that those permissions are automatically enforced by our RAG system
Getting Production Ready: Ensuring Correctness
Firstly, LLMs are known to occasionally make things up, and we really don’t want our Sales people to get a reputation to making up answers to customer security questionnaires. Although using RAG to supply the security documentation should significantly mitigate complete hallucinations, we still likely want our infosec team to have some oversight into what the LLMs are saying, making sure those answers seem right, and providing the relevant context citation to help the end user understand the reasoning behind the answer provided by the AI system. Getting Production Ready: Data Protection
Secondly, we may not want our data going to OpenAI, or at the very least we likely want some level of protection and audit logging around sensitive information making it into OpenAI’s training sets (and so we can do RAG reporting) and the SOTA in large language models can change rapidly, and for business prudence reasons, we may not want to build in a business dependency on OpenAI, especially if they are not necessarily serving the best RAG models.
To solve this problem, we’re likely going to want to do three things:
- Negotiate agreements with all the LLM providers to ensure they are not training on our data, manage all those DPAs with the now dozens of providers in the space.
- Add a system to surface responses to infosec SMEs (or subject-matter-experts) who can ‘approve’ or ‘reject’ an answer, and where needed, correct it for SMEs. The cherry on the cake here is that future answers to similar questions should hopefully now be better than previous ones, and from a security perspective, we get thorough RAG reporting.
- Ensure citations are provided in the LLMs response
And there we have it: the production worthy version of the very simplest of all possible LLM + Data chatbots, a security chatbot that can answer questions on our security documentation accurately, improves over time, can be appropriately overseen by our SMEs, won’t leak any sensitive information to OpenAI and can be easily updated to the latest and greatest RAG models. Of course, this is still very much a minimum viable product - good to enough to ship, good enough to create actual value for users, but definitely not yet the finished article.
RAG Development Step 4: Ongoing Improvement
If we expect an average of 5 questions per day, a year in we'll have over a thousand questions answered. If 5% of those have corrections by SMEs, then we'll have 50 corrected answers we'll have to check for each prompt. That will start to use up a lot of the context window, and may harm performance. Instead, it might be better to just select only the most relevant historical examples to provide to the prompt (this is called "Few Shot Learning". Equally some of those corrected answers will prove stale over time, so we'll need a way to expire or edit previous corrections. Prompt engineering lessons will be learned on how to get get reliable, honest, good answers, and your sales teams are unlikely to be good at prompt engineering out of the box. Forcing them to learn everything about prompting risks turning them off entirely, so most systems end up putting certain basic ideas from prompt engineering into a system prompt, which automatically makes the AI more helpful when answering the user's core prompt. Similarly, a naive implementation of the Slackbot will actually involve a long wait time for a response for the AI, and so its common to add a little Slack reaction emoji to demonstrate that the AI is thinking. These little finishing touches can wait, but they really improve the user's experience overall.
Conclusion
RAG Development is just like software development, and building a Security Chatbot is super easy at prototype stage, and a little trickier in production. Of course this is still only a very simple usecase, and so for highly technical organizations this kind of usecase is still very possible in house. But for more organizations they'll have to choose between prioritizing internal development efforts on building such a chatbot from scratch, or procuring a platform that makes it really easy to make one. Either way - your sales team will be happier getting answers faster, and your infosec teams will be too, being far less bothered by unexpected Sales interruptions!


