Building an Onboarding Buddy: An AI Tool to Help Me in My New Role
September 20, 2024
Who Am I and What Do I at Credal?
This is my first time writing here, so nice to meet you all! I joined Credal earlier this week as the first business hire, focused on all things GTM. As I went through my first few days here, I found myself asking basic questions that surely must have been previously answered or documented someplace. My mind went to building a Credal ‘copilot’ to help me with future questions and new hires as they join. What better way to help me onboard at Credal than using Credal? Although I have a degree in Mechanical Engineering, I am by no means a software engineer, so follow me on my journey of building with Credal.
What Is a Copilot?
Think of a copilot as a dedicated assistant who is an expert on the data and context of your company, team, or even a specific workflow. Using AI, a copilot can provide you with contextual information on your questions while citing the sources that it’s pulling from. In this case, we’ll call our copilot an ‘Onboarding Buddy’ that can help new hires with answers to anything a new hire at Credal might need to know: from the office wifi password to specific product questions like what the security features that Credal offers are.
How I Went about Building My Copilot, and the Considerations along the Way.
Getting Started
Credal has a quickstart guide on copilots, which I found through the documentation. The documentation was easy to find through the website header.
This gives me everything I need to get started.

Configuring My Copilot
Once I added my Onboarding Buddy as a new copilot, I was faced with my first non-trivial selection for the configuration, what model do I want to use? Credal supports all OpenAI and Anthropic models, so I decided to go with GPT-4 Turbo for familiarity’s sake.
Next, I wanted to provide some background context to the copilot on what Credal does, who the intended users of this would be, and what kind of questions it can expect. Given the target audience and the expectation of a ‘buddy’, we should also probably shape the personality of the copilot to be friendly. I input the following into the background prompt:
“You are supporting employees at a startup called Credal. The intended users of this copilot will be new employees within their first few weeks or months on the role. Users will be coming to you when they have basic questions that need to be answered that would be quicker than asking other employees. You are a friendly, supportive, and honest assistant, who helps company employees answer questions and prompts truthfully.”
Connecting the Data
Now that we’ve got the basics set up, it’s time to connect the data that I want to provide as context. There are a few sources that I want to include:
- Slack channel (#general)
- This is Credal’s primary channel with all members of the team, dating back to the start of the organization, so this should provide historical context over the last 1+ year.
- Slack channel (#ask-anything)
- This is a slack channel that has all of Credal’s internal copilots deployed [more on that later], so this should be helpful to our copilot if I’m repeating a question that’s been asked before.
- Google doc (Onboarding FAQ)
- This was a document created by me, listing questions and answers of items I wanted to find but couldn’t.
I have two options to integrate this data into the copilot as ‘search sources’ or ‘pinned sources.’ Let’s review the descriptions of both options below to understand my decision-making on where the data should live.
"Search sources work by breaking documents into chunks of approximately 1000 characters each and storing them in a search database. User queries are then compared against these chunks to find the most relevant matches to pass to the model as context.
This is useful for finding relevant information across large documents that can't fully fit in an LLM model's context window.
Pinned sources configure the copilot to include the entirety of a document in the context window when generating a response.
This is useful for relatively small documents that can fully fit in a model's context window and where the full document contents are needed for generating a high quality answer."
Given there are only a few sources, and the LLM should need all the context to provide an accurate answer, I’ll place all three as pinned sources.
Initially Testing Queries
Now that we’ve configured the copilot, provided it with the relevant data sources, we’re ready to preview and test some queries! Let’s try asking whether I need a badge/key to enter the office building. The answer I’m expecting is that I need a badge to enter the building outside 9 am and 5 pm, but it shouldn't be necessary between those hours. This is documented in the Onboarding FAQ document that states:
Question: How do I enter the building?
Answer: You can enter the Greendesk building between 9 am and 5 pm and use the elevators without a badge. Outside those hours, you will need a badge. The 3rd floor requires a badge to enter at all times. Credal’s office space requires a physical key to unlock the door.
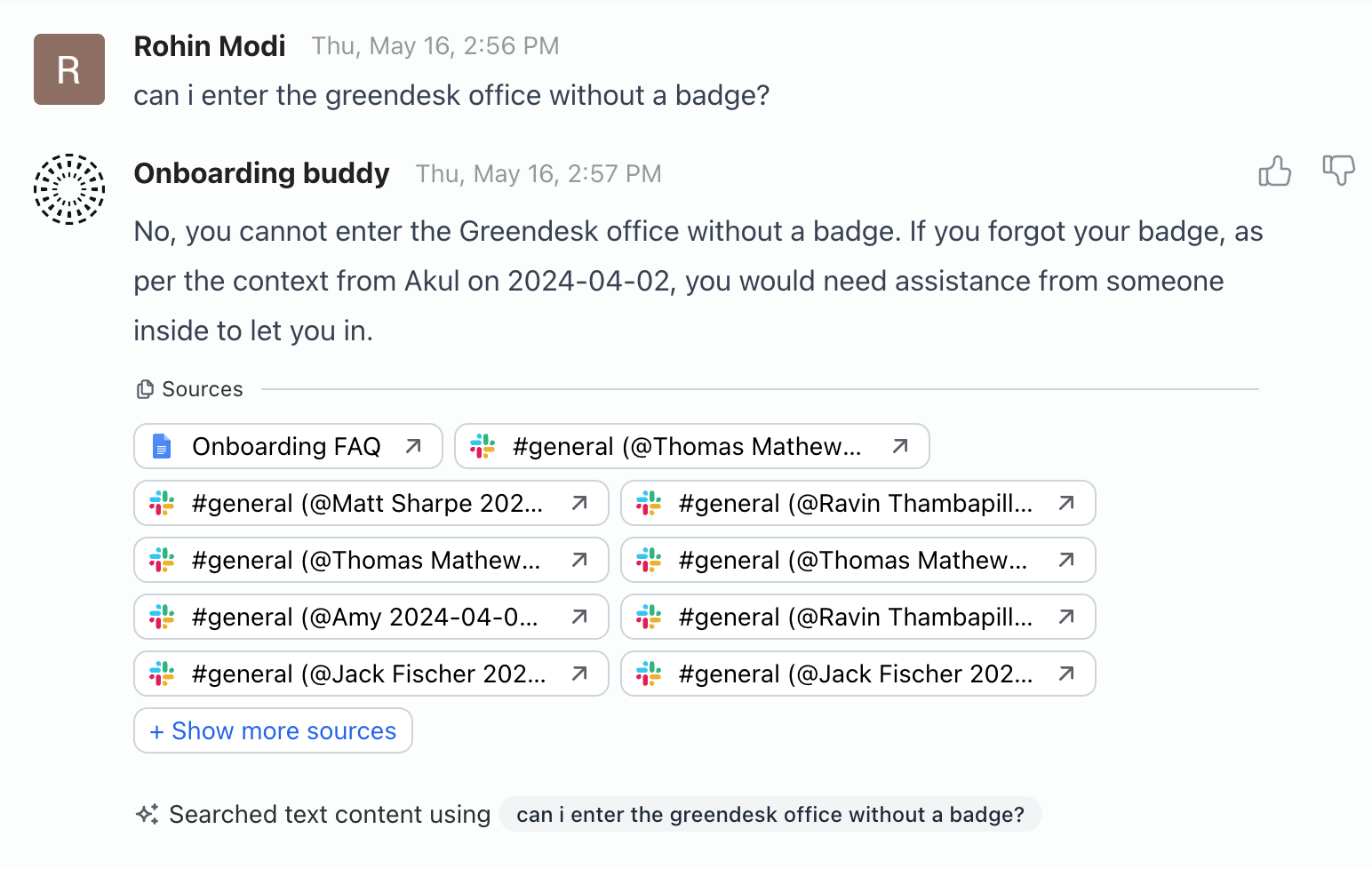
That’s not quite what I was expecting. It seems like the LLM has focused on a specific slack conversation, without entirely referencing the FAQ document that it may have looked through briefly. Would another LLM, like Claude, perform better here? I’ll switch up the configuration and run the query again.
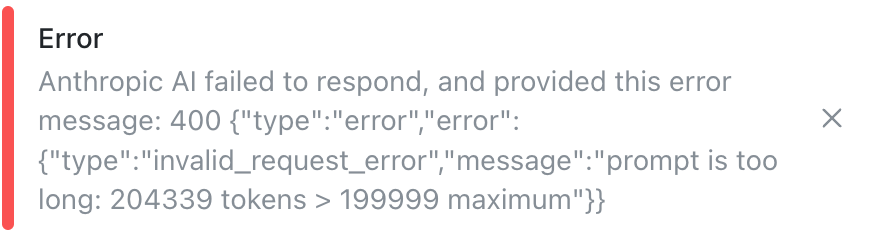
Well, that’s definitely what we were looking for. Although, seeing that we’ve overloaded the LLM’s context window, we now have an indication about the root cause. We’re passing too much data to the LLM, let’s take a look at our data sources in the copilot configuration.
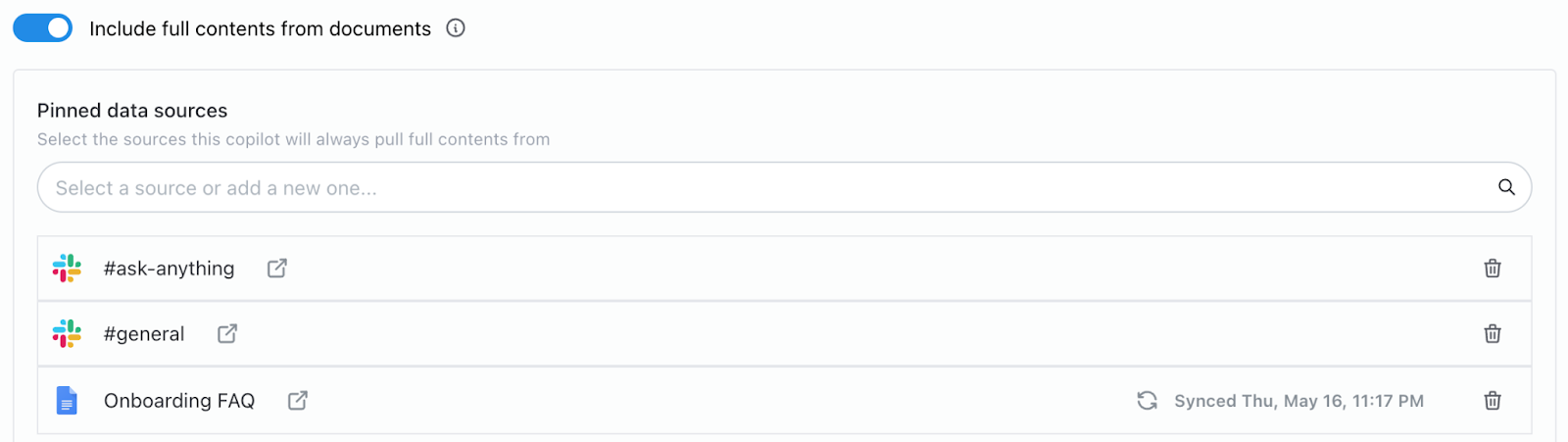
My initial thesis was that the LLM would need all these data sources for each query to provide an accurate answer, and hence they should be placed as pinned sources. However, we are clearly overloading the LLM with context, and it is unable to provide an accurate response to a question that is directly answered in the Onboarding FAQ doc.
Re-Configuring the Connected Data
Let’s see how we can optimize this. From these three sources, the two slack channels include messages dating back a year, and probably don’t need to be passed to the LLM in their entirety for every question. There is also no ‘retrieval’ performed in this instance as all three sources are included in the context window for every query. Re-thinking the split between search and pinned sources, we can probably leave Onboarding FAQ as a pinned source, given that the most common question/answer pairs will be listed there and should be straightforward for the LLM to contextualize. The two slack channels, however, can be moved to search sources, they include a wide range of data that might not be relevant to my question, and Credal can semantically retrieve the relevant content as context for the LLM.
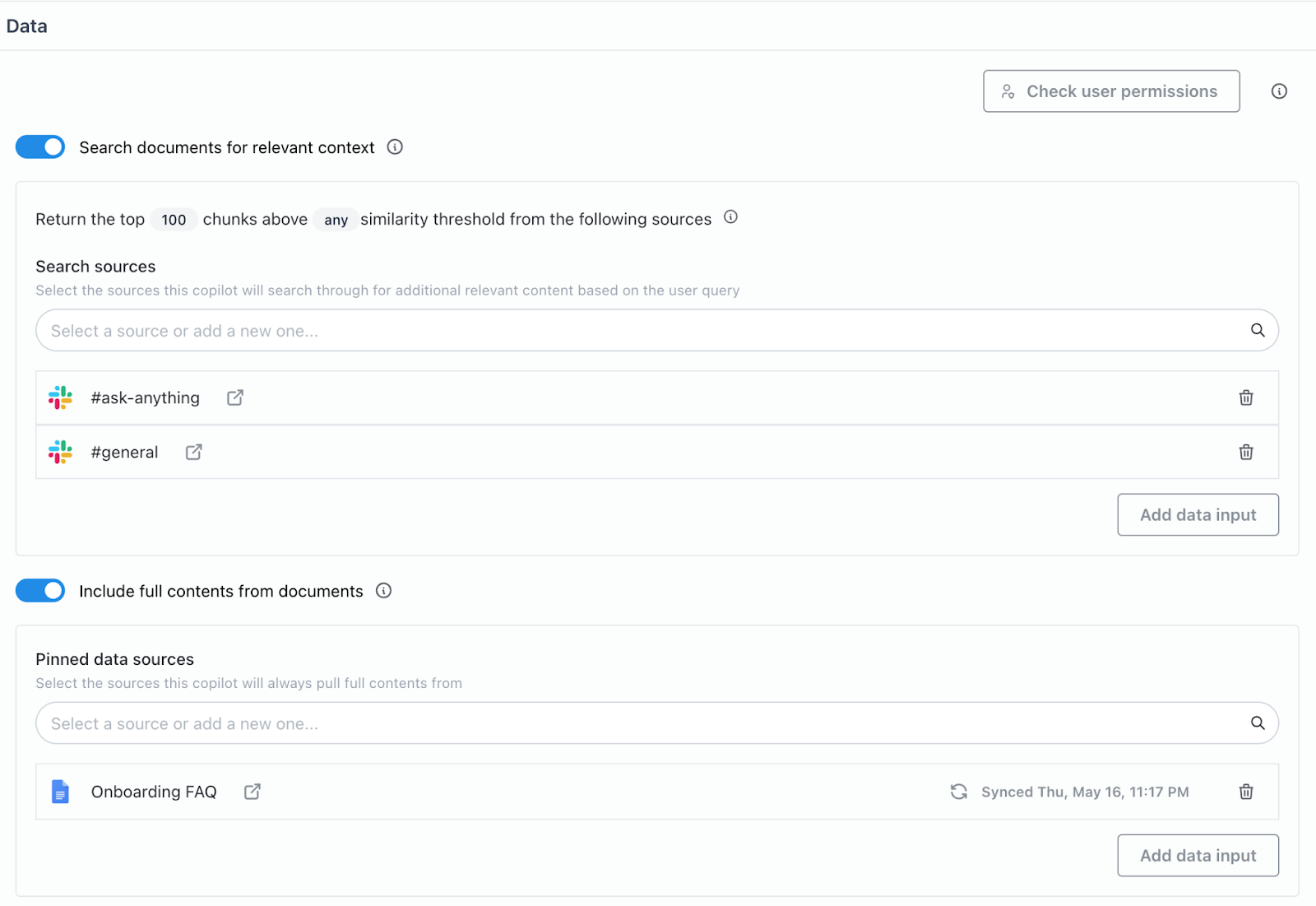
Further Testing Queries
Now that we’ve re-configured the data sources, let’s retry my original question:
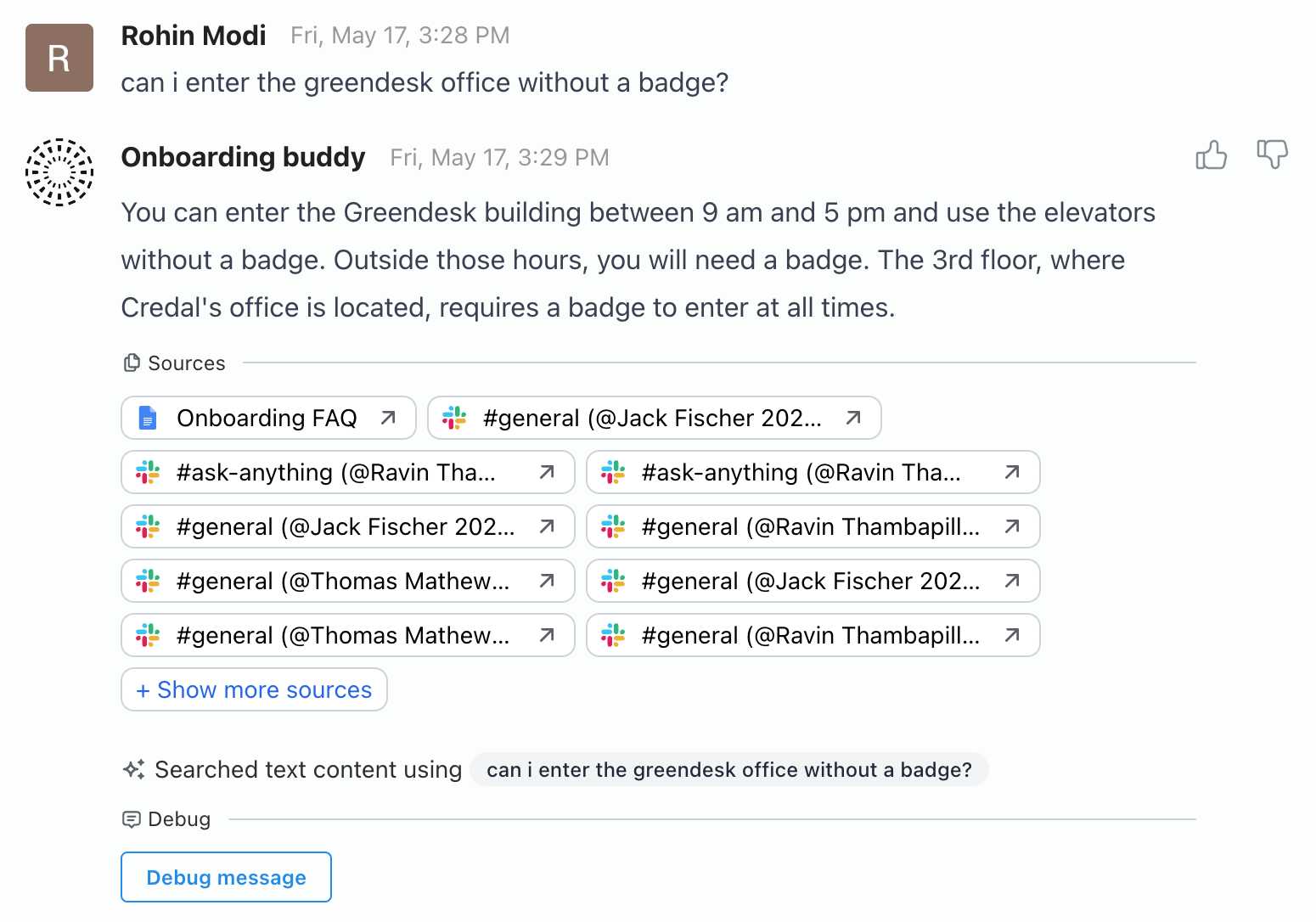
Success! The LLM was given the relevant data from the Onboarding FAQ, along with some of the slack channel messages retrieved by Credal and was able to generate an accurate answer.
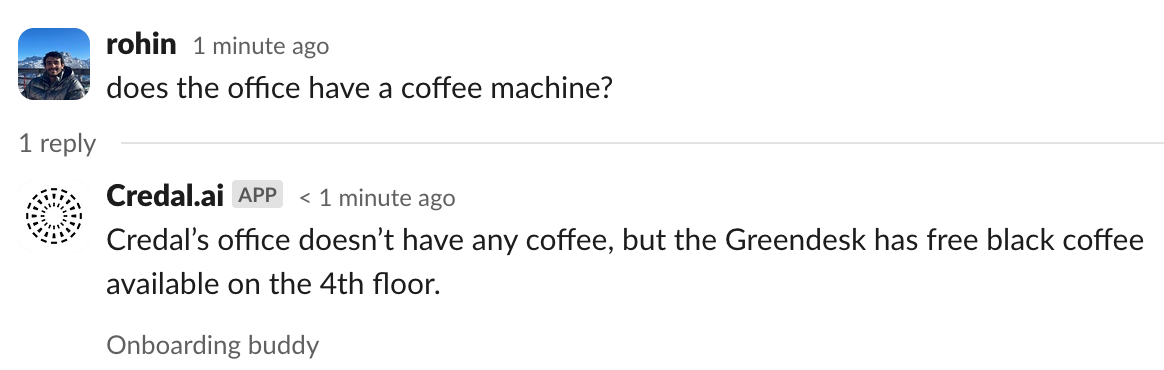
Let’s try asking another straightforward question:
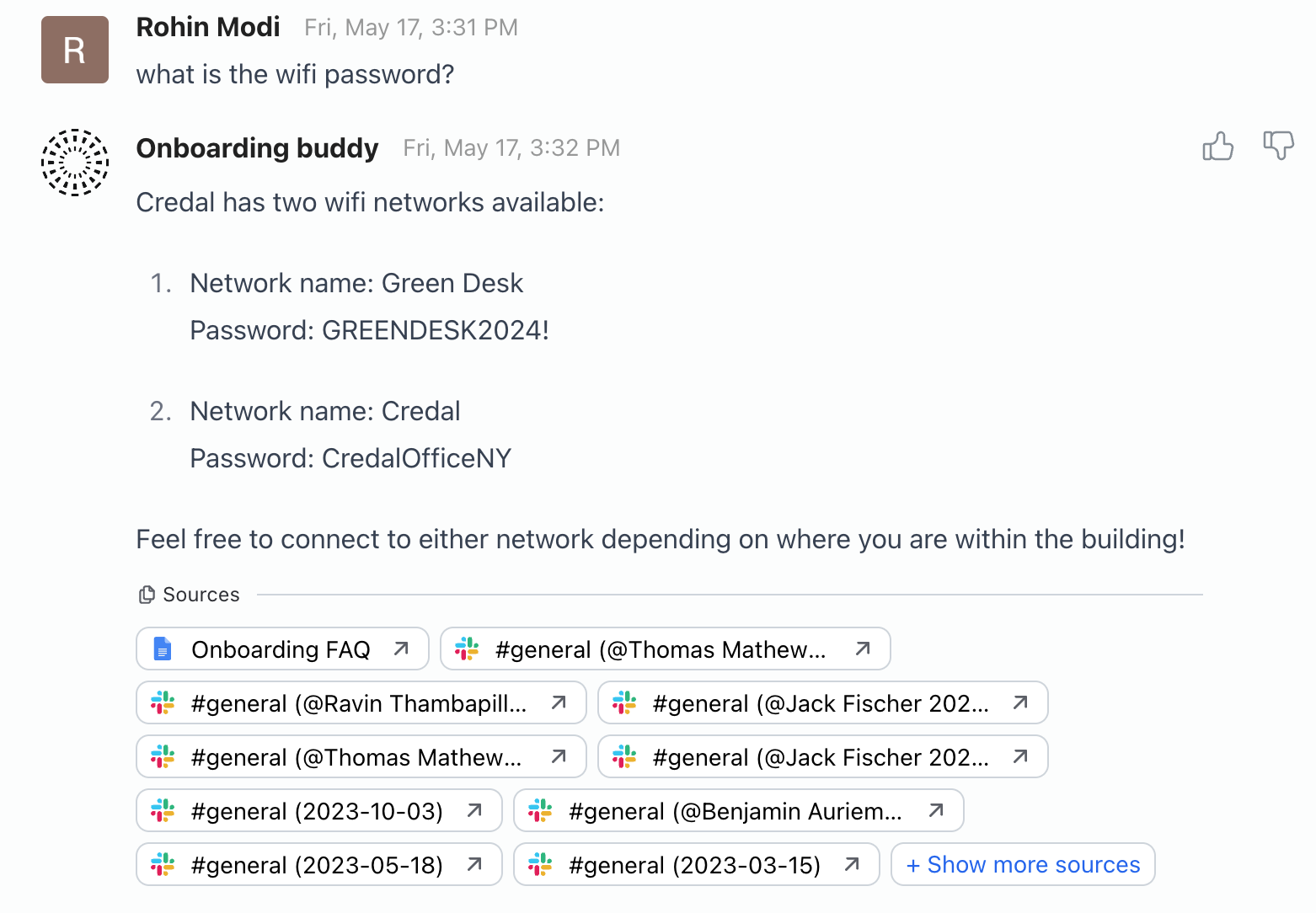
Note: The WiFi passwords listed in the image above have been modified for security purposes.
Nice! The copilot is generating responses as we would expect. Now that we have an accurate and functioning copilot, we can deploy it. I want to deploy it to the Credal Web UI, which will allow anyone to interact with it on the web app. I tend to spend a lot of time on Slack, so I also want to have a way to access it directly there. I created a channel called #onboarding-buddy that the Onboarding Buddy copilot is deployed into and will respond to any message sent.
The outcome and what I learned as a result
Taking a step back, the primary goal of this project was to familiarize myself with building with Credal, and providing future new hires a tool that they can use as a companion when they first join. Some of the secondary goals were to understand how retrieval augmented generation (RAG) and LLMs work, and how they can be implemented to improve productivity.
We successfully built a copilot that uses internal data to support an onboarding process by providing contextualized answers. Both our primary and secondary goals were met.
My key takeaways from this process:
- Credal is really easy to build with
- As a non-technical person, I was able to work on the project from start to finish with minimal outside help, it was straightforward to connect the data sources I wanted to use, configure the copilot with intuitive controls, and deploy it to external locations with the click of a button.
- LLMs need to be fed the right information
- I initially believed that sharing all the data available would be beneficial to the LLM in providing an accurate answer, however, the opposite was true in practice and the context window was overflooded. The key is not necessarily providing as much information as possible, but it’s about providing the right information. RAG platforms such as Credal will pull the relevant data from the right sources based on the query, and give the LLM sufficient information to generate its answer.
- Data is powerful, if kept secure
- My previous interactions with AI tools have mainly been tools such as ChatGPT or Perplexity, but I didn’t tend to incorporate them into my workflows as they didn’t significantly lift my productivity. There are probably several reasons for this, but one of the main reasons being that those tools didn’t have the context on what I was working on and the documents that I’m referring to for my work. Having the ability to ask questions on your data truly moves the needle on usability. However, this raises the question of security. As more and more companies choose to build AI apps on top of their data, security functionality like permission-aware data integrations, PII redaction, and audit logging (more on that here) will become paramount.
This was a fun and educational project, allowing me to get acclimated in my first week, using our own product. Thanks for following along! While Credal is a smaller company, you may have more data sources (Notion, JIRA, Confluence, etc. are examples that we support out-of-the-box) that you’d like to pull from, so feel free to reach out to me and I’d be happy to help with any questions, rohin@credal.ai.