How to embed AI Agents into daily workflows at enterprises
March 11, 2025
Why haven't AI agents truly transformed enterprise workflows yet?
Every enterprise is thinking about rolling out AI agents internally, but most haven’t figured out how to make an agentic platform actually transformative for the business.
Getting users to adopt AI for easy tasks like improving wording on emails or summarizing meeting notes is straightforward, but it doesn't make an organization feel like a radically different place to work. At best, it's a nice little time saver. At worst, going back and forth with the AI is even more time-consuming than doing everything yourself start-to-finish.
That's because in practice, knowledge workers are primarily paid for doing three things:
1) Strategizing with their colleagues
2) Expertly executing a workflow
3) Reflection and improving
You aren't paying people to summarize meeting notes; it’s just a side task they have to do. So until AI enters the core workflows, it stays relegated to these side tasks without actually impacting the business much. So the main reason that AI isn't used end-to-end is simple: you pay a knowledge worker not just for executing the task, but for their expertise, their ability to strategize and collaborate, reflecting, and improving.
How do we get AI Agents to actually get daily usage?
The big question today is how does AI get closer to performing operations end-to-end? The research labs like OpenAI and Anthropic promise “AI agents” as the solution, with the ability for everyone who uses them to do more, work faster, and work smarter. While many have played around with impressive demos from OpenAI’s operator, its still mostly the case that these tools are not yet viewed as production ready.
While agentic frameworks sound cool and often have impressive demos, the practical reality is that Enterprise Software need high reliability, accuracy, and security - all things these Agent demos currently lack. Without giving a human knowledge worker the ability to really embed their expertise into the system, the potential of fully autonomous agents is inherently limited to side tasks that do not require much (or any) expertise.
To get these AI Agents into production at Enterprises, we need to focus on providing deep explainability into agent decision-making processes, and creating feedback loops to allow for knowledge workers to effectively transfer their expertise into the system. For example, an AI agent whose job is to review applications to a fintech company and determine whether or not the application is a legitimate business or not, will need a lot of coaching to help it get better at distinguishing legitimate from fraudulent documents, identifying edge cases that suggest suspicious transaction patterns, or being able to distinguish reliable, trustworthy websites from the considerable amount of noise on the internet.
How can AI Agents build up accuracy from the enterprise over time?
At Credal, we solve this by beginning with comprehensively integrating an organization's relevant data sources into an Agent’s knowledge, connecting the critical documentation from Google Drive, Microsoft Office, Confluence, Slack, Salesforce, Jira, and other systems that contain valuable information about how this Agent should operate.
Once the data is integrated, we enable subject matter experts (which could include virtually everyone, as each person manages unique responsibilities) to design copilots with customized prompts, data sources, and training examples that reference either your entire organizational knowledge base or specific collections relevant to particular workflows.
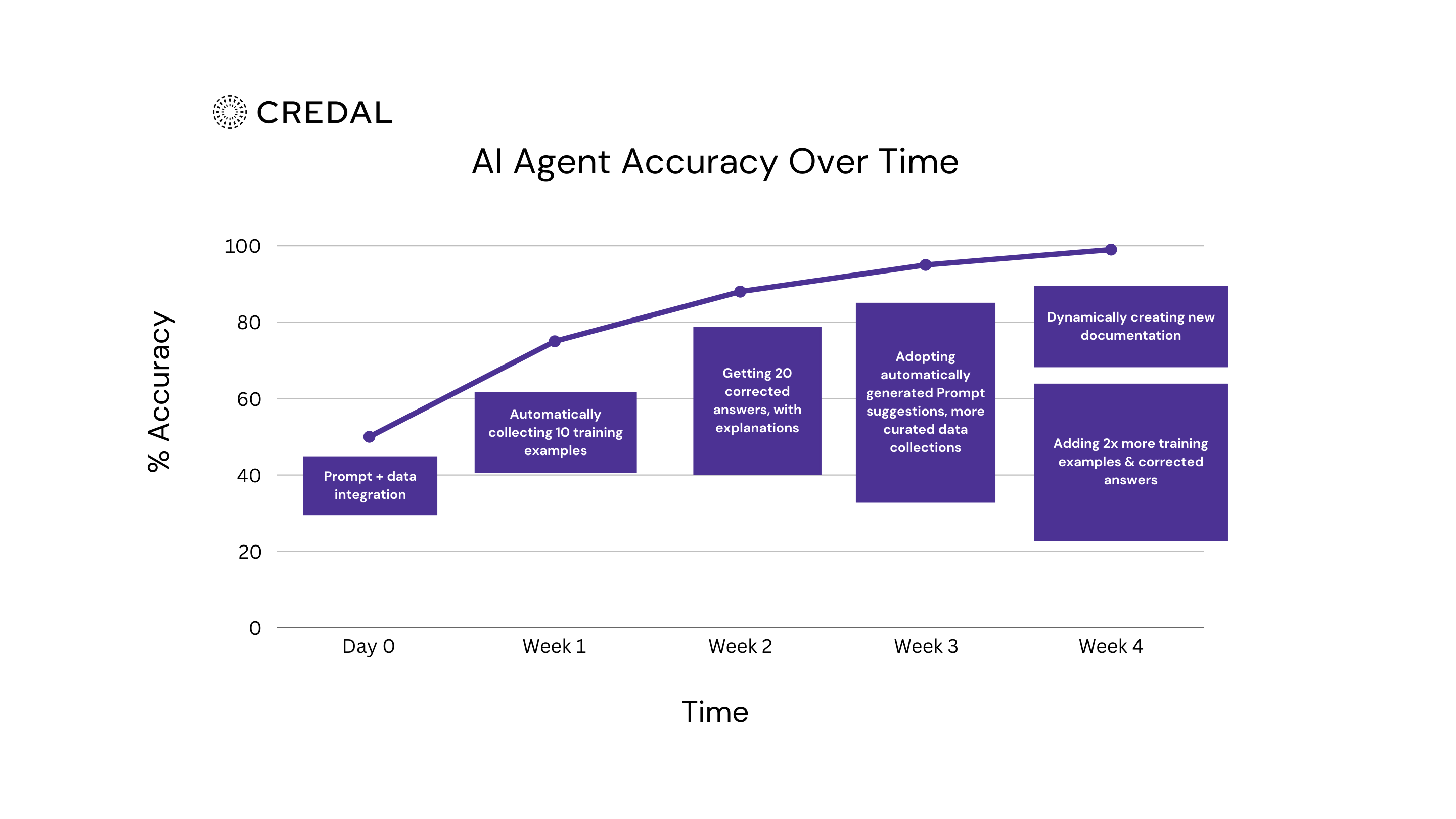
AI agent accuracy over time with Credal
Day 0: Achieving initial results with AI Agents in 5 minutes
It only takes 5 minutes to spin up your MVP agent built with a prompt that’s connected to the relevant internal data. While it’s helpful to have a custom prompt layered on top of your data, as you may have already experienced with other tools, it may only get 50-60% of your user’s questions correct. Something like that, while helpful, is unlikely to make your enterprise feel like a radically different place to work.
Week 1: Improving AI Agent accuracy through feedback
By the end of week 1, the Agent should see a significant improvement from Day 0. This is because as questions come in through your Slack channels, the Agent will have tried answering them. For the 50% that it got right, the subject matter expert will simply give it a thumbs up. For the questions it got wrong, the Agent will actively ask “Why did I get this wrong?” You’ll be able to either 1) Tell the copilot what’s wrong, or 2) Provide a “good” answer - and your response will get added automatically as training data.
Every feedback response is logged for full visibility, so that any collaborators of a copilot (or even any user!) will be able to see exactly how the copilot behaved and why.
The Agent provides a full chain of its reasoning, the data it looked at, and why it came to the conclusion it did. Then, the subject matter expert can simply note which part of the chain went wrong: Was there some missing data? Did it prioritize a Slack discussion over the Confluence wiki, when the wiki is the right source of truth? Before long, you’ll have identified 10+ training examples, which come directly from the most frequent types of questions your users actually ask.
When a new query comes in, the Agent will determine which training examples are most relevant to the current question, get better at understanding which data sources to rely on, when they might be missing data or context, how to distinguish between undocumented behavior and a product bug, etc.
Credal automatically generates suggestions to a subject matter expert for how to improve their copilot, so this process can be as easy as clicking a button or asking the copilot to update the documentation.
Here’s an example taken from one of our GTM copilots at Credal, a standard competitor assistant.
First, I ask the agent for the differences between us (Credal) and a competitor.
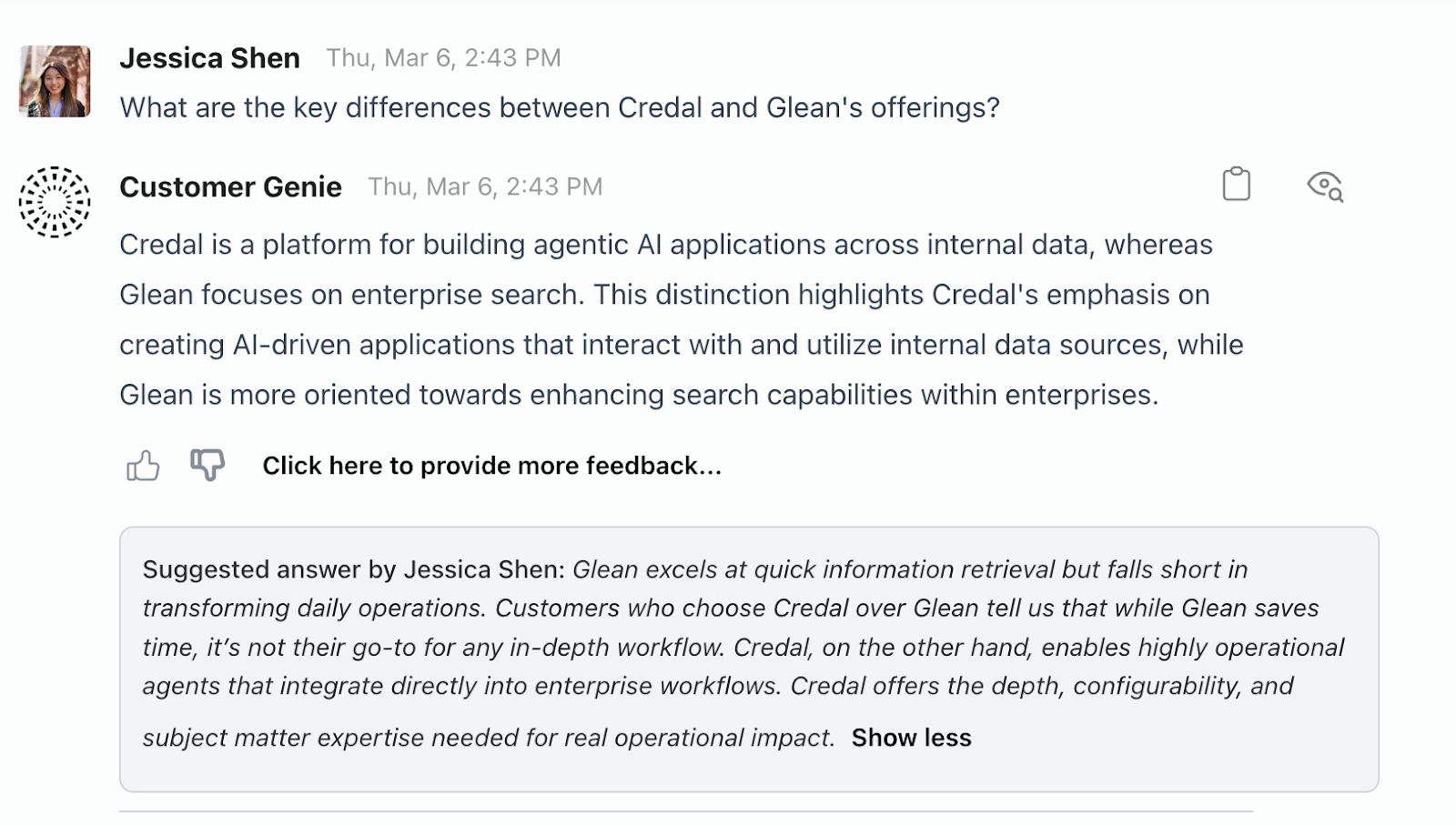
Next, I ask the agent the same question. Because of my manual fix, I get the result I'm looking for and mark it as a strong training example so that anyone on my team who has the same question in the future will get the intended answer.

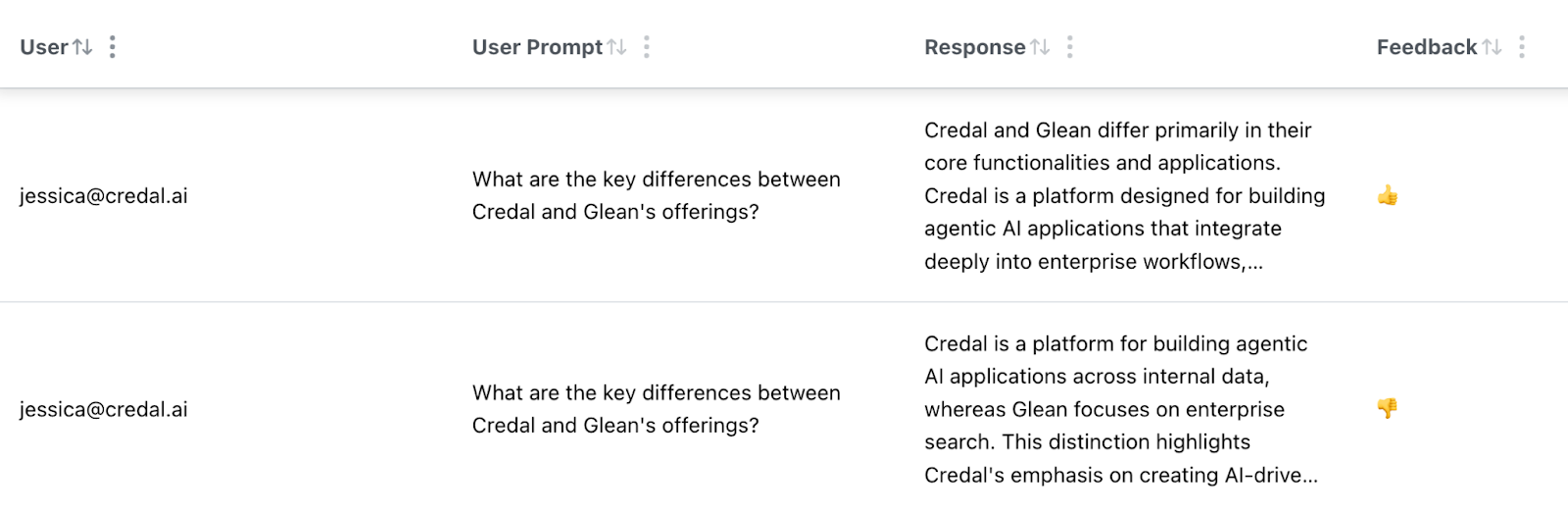
Finally, I'm able to view the audit logs to see the historical prompts, responses, and feedback to evaluate the types of questions being asking and how well they've performed to identify patterns.
Week 2: Scaling AI Agent performance through feedback loops from your team
By the end of week 2, you'll have been able to deploy this copilot to the rest of your team, which should generate an influx of feedback - this is key. With more users interacting with the Agent, you'll rapidly accumulate valuable training data in the form of corrected answers and explanations. Aim to collect at least 20 high-quality corrections during this period, focusing on edge cases and nuanced scenarios that frequently trip up the system. This collective expertise should generate a positive feedback loop where each correction improves performance for all users. The Agent will begin recognizing patterns in its mistakes and proactively flag similar situations for human review, dramatically accelerating the knowledge transfer process from your experts to the system.
Week 3: Automated prompt refining and curated data collections
By the end of week 3, you'll have been able to make significant improvements through two key mechanisms. First, you'll adopt automatically generated prompt suggestions that Credal identifies based on usage patterns and feedback data. These refined prompts better capture the intent behind common queries and further direction on what the output should look like. Second, you'll develop more curated data collections, allowing the Agent to prioritize the most relevant information for specific workflows. This targeted approach means the Agent becomes increasingly precise in how it navigates your organization's knowledge landscape, reducing hallucinations and irrelevant responses by over 40% compared to week 1.
Week 4: Reaching 99% accuracy with AI Agents for true business transformation
By the end of week 4, you'll have transformed your Agent into a truly mission-critical system. The Agent will be dynamically creating new documentation based on interactions, finally capturing tribal knowledge that previously had no systematic way of being documented within the organization. You'll have added at least twice as many training examples and corrected answers as you had in week 2. At this stage, the Agent doesn't just answer questions - it begins anticipating needs, suggesting process improvements, and identifying knowledge gaps in your documentation. Users report spending 30% less time on routine tasks, and more importantly, the quality of their work improves as the Agent helps them access the full breadth of organizational expertise at exactly the moment they need it.
Getting an AI Agent platform with daily usage in core workflows
The journey from a basic AI assistant to an AI agent platform that every employee uses religious isn't actually about better technology, it's about embedding subject matter expertise into AI capabilities in a way that actually works, beyond just prompt engineering. As the Agent learns from that expertise, institutional knowledge accessible to everyone who needs it, exactly when they need it.
What makes this approach different is the continuous feedback loop that allows for every interaction into an opportunity for accuracy improvement. The transformation comes from 1) creating a systematic way to document tribal knowledge, 2) feeding that into a system that continuously improves, and 3) allowing these systems to get collaborative input from everyone and be used by everyone.
What’s next?
Ready to see how a truly mission-critical AI Agent can transform your enterprise? Book a demo below to get started and change what your team can accomplish.


