How LLMs are helping Enterprise SaaS teams close more deals and build what their customers want
September 21, 2024
This is the second post in a series of case studies on the deployment of LLMs in real-world settings. The first one is here, on AML.

Sales calls contain valuable data, but companies rarely make use of this information. This includes questions around market demand, product bugs, sales commitments, and so on.
With LLMs, this changes. Getting the answer to complex questions is now a simple case of asking the AI.
At Credal, we’ve been working with the product team at a large, multi billion dollar software company on this exact question: they wanted to get more visibility into the signal that sales teams were getting in sales calls, especially around new product offerings.
The types of questions their product team was interested in included:
- “Which customers complained about slow response times from the API?”
- “Summarize the feedback we’ve received from prospective customers about the demo of the ABC product”
- “Which customers have we made sales commitments about features that have do not have an explicit ETA in the product roadmap?”
The technical challenge
This customer was using Chorus to record sales conversations, and they were piping the content of those conversations from Chorus into Snowflake, where it was hooked up to contextual data from Salesforce. The challenge was to help them ask question of this data.
As in our previous case study, we saw a similar set of problems:
- How to connect the data from Snowflake into a tool that would let them easily ask these kinds of questions?
- How do you manage the permissions of who could see which call transcripts?
- How to configure retrieval to accurately get back the right context for these queries?
Challenge 1: Get the data into a format the LLM can understand
As usual, Credal makes connecting data from these systems easy with our Snowflake Connector. Just a few clicks and your structured data is available for querying:
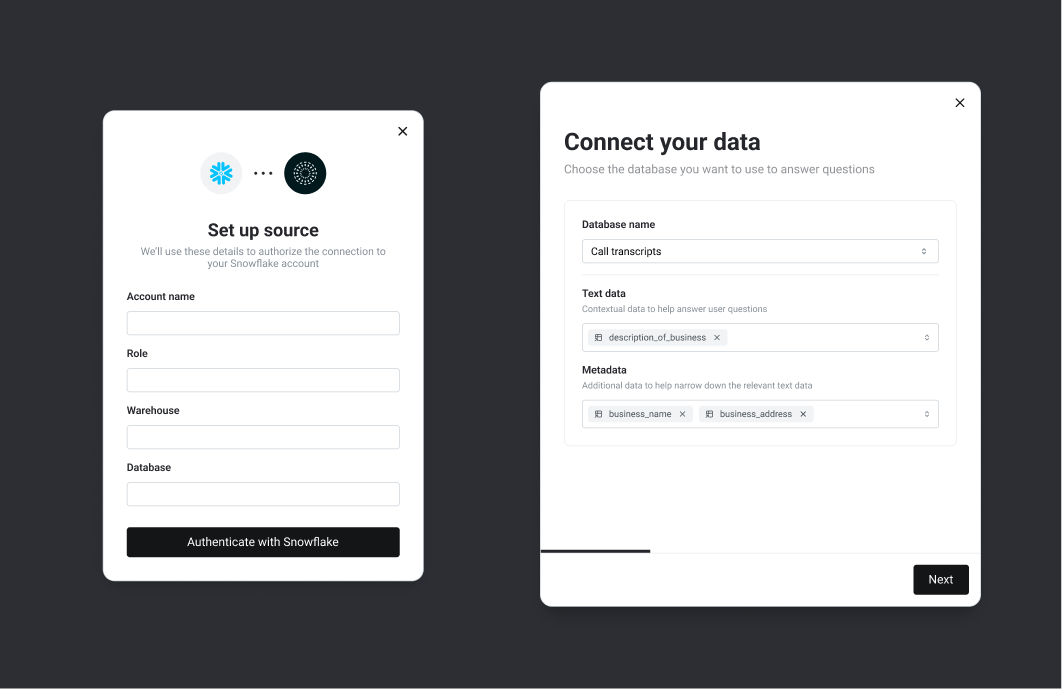
With that complete, any company-approved LLM can now access this data on behalf of an authorized user. Each call transcript is treated as a piece of context potentially relevant to any given user question. Together, all the call transcripts are considered a “collection”.
A user can now configure a Copilot to use one of these collections as a source to search through for relevant context.

Now when a user asks a question, they can specify if they want to use a specific transcript, this entire collection, or even the entire universe of data at the enterprise - as a source for the relevant information for this problem.
When Credal passes the data to the LLM, we’ll pass not just the transcript of the call itself, but also the relevant context (which customer, what date, etc). That makes it much more likely that more sophisticated questions will be answerable.
Challenge 2: Managing permissions to the underlying data
Call transcripts sound simple enough, but it gets tricky when they’re permissioned.
For example, say it’s a call with government officials; who gets access to that, and how do we make sure the LLM respects those permissions when searching those transcripts? Almost 25% of our customer base are organizations that sell to governments, who have high-bar data processing requirements, so this is an essential requirement for those kinds of businesses.
There’s a few different approaches you can take to managing this kind of information.
The simplest is mirroring permissions: if the data is largely in a CRM like Salesforce, you can simply have Credal mirror the source permissions of the data in Salesforce. That way Credal will reach into Salesforce, figure out who has access to what data at Salesforce, and then automatically provision access in Credal according to the same rules.
This gets a little more complicated when the data in Salesforce is commingled with data from other tools inside Snowflake. Often the data in Snowflake is just locked down to developers and the data team, which would be useless in this case, since the point is to expose the relevant data in Snowflake to the product team and sales teams. You want the US product and sales teams to have access to all commercial calls and US government notes, the UK teams to have access to all commercial calls and UK government notes, and so on.
This requires row-level access policies. In Snowflake, the user specifies a column to use to define access policies. This provides a single column with a list of OKTA group ids, that define which people should have access to that data. Now, we can create a group in OKTA called “UK Sales team”, and a group called “US Sales Team”, and a similar one for the product teams. From here, we tell Credal to use that column to provision access on a row-by-row basis (aka, row-level RBAC). When a user changes role, they’ll be moved out of the OKTA group and immediately lose access to the data in Credal. Magic!
Challenge 3: Consistently retrieving the right data to answer the question
Sales calls usually involve a large volume of data; often this is too much to include in the context window every time. So we need an intelligent retrieval strategy.
The default, naive implementation of semantic search with LLMs would be to:
- Embed the transcripts
- Embed the user’s query
- Look for transcripts that are similar to the user’s query, using a technique such as cosine similarity ranking
Unfortunately, the naive method does not perform well at all for a few reasons:
- Naive vector search doesn’t always retrieve the right type of information. For example, a user might reference the ‘product roadmap’ in their query (e.g. “Are there any cases where we have promised a feature to a customer that we have not committed to in the product roadmap?”). The naive method will typically not pull back the full contents of the product roadmap for that kind of question, but seeing the full roadmap - alongside the specific commitments or promises, is necessary for the LLM to perform its job in this case.
- Keyword approaches are often better for some common use cases. If a user wants to ask about a specific product feature, and really wants to see all mentions of that specific feature, naive vector search can often lose out to more straightforward keyword approaches.
- Information overload. The sheer volume of transcript data means that there are going to be a lot of cases where a section of a user’s transcript might seem superficially to be very similar to the user’s query, but actually it just doesn’t hold that much relevant information to help an LLM actually answer the question.
Doing retrieval well is an extremely complex and deep topic, which we’ll be writing about extensively soon. But some of the tricks we’ve found while building Credal (the market’s leading RAG platform) that can help:
First, let a user define a document to ‘pin’. This means specifying that the content of this document should always be available to the LLM. This lets us say for a small document, like a product roadmap (small relative to the full set of transcripts with every customer), that we need to keep this always in context. In this case we might want to pin the product roadmap (or let the user decide whether to pin the product roadmap when they ask the question)
Second, reranking and hybrid search. We use Cohere’s reranking endpoint, which helps improve the ordering of documents by taking the results from the naive vector search query, and asking a small LLM to quickly check which documents are relevant to the question. This helps in weeding out documents that are superficially similar to a user’s query but do not actually contain any context relevant to providing an answer. Our research indicates that adding a keyword component to the search also helps search rankings.
Third, metadata filtering. Before sending the query to the LLM, you can add a step in the chain that figures out intelligent filtering criteria. For example, a user might ask to narrow the search to a specific timeframe (“in the last month”), or from a particular customer. In that case, naive vector search is going to perform badly at doing that narrowing. Thus, when user questions require narrowing the scope of documents according to one of these metadata fields, it’s smart to have a step in your chain that figures out from the user query what the right values to filter on are, (e.g. if your metadata fields are, “date”, “customer name”, “customer vertical”), stitch in an LLM call that identifies which fields the user wants to narrow down on, and what values they want to narrow down to. Once you’ve got that back from the LLM, in a structured format like JSON, you can filter your results down to the subset the end user is interested in.
We’ve found that this is especially useful for dates, because if a customer asks for feedback from Customer X, and you accidentally include feedback from customers X, Y, and Z in the context, the most powerful LLMs will usually do a good job of narrowing in on the feedback from customer X. But for some reason, we see a lot of cases where the LLMs struggle to properly understand a request like “give me feedback from the last month.” This seems to be a fundamental reasoning challenge that LLMs have at the moment - hopefully we’ll see this improve in future model versions!
Wrapping up
Being able to connect an LLM to structured data can unlock the second order, non-obvious use cases - if you have the right governance and retrieval infrastructure in place to use that data effectively.
We view it as fully proven in the industry now that providing a good chat interface on top of a corpus of existing enterprise documents, like a HR / Benefits handbook or Information Security Policies, can provide a lot of value to end users quickly.
But to unlock these second order, more complex use cases, we typically see a significant need for companies to be able to hook up data from more than just PDFs or Google Docs. LLMs need to be able to read from spreadsheets, databases, images and external websites in a way that is governed and access-controlled appropriately, in order for Enterprise AI usage to move away from the toy chatbots into more real world, high-value use cases.
If you’re in a regulated industry or want advice on dealing with these issues, or want to arrange a demo of our platform, feel free to contact us and we’d be happy to help: founders@credal.ai