Build your own RAG Enterprise Search in 10 minutes with Credal & MongoDB
February 06, 2025
Summary
Retrieval Augmented Generation (RAG) and AI agents are fast becoming the two key use cases for Large Language Models (LLMs) like ChatGPT at enterprises. Many use cases for RAG, like HR bots, Security Questionnaires, Onboarding Assistants and more, rely on data from sources like GDrive, Slack, Confluence and other internal SaaS tools. However, to run RAG using data from these tools, enterprises need three things:
- An operational and vector database layer to store both vectors and operational data for running your RAG application
- Permissioned Data connectors to ingest data from Google Drive, Slack, Salesforce, Confluence etc in a way that respects the underlying source permissions of those systems
- A configurable UI or APIs that allow users to create copilots that can power applications with agentic behavior on curated subset of data along with extensible capabilities such as custom prompting, Web Search or Code Interpreter
Credal combined with MongoDB can provide an Enterprise all of these, and get set up in less than 10 minutes. This blog shows you how to do exactly that.
Introduction to Credal
Credal provides a secure, flexible interface to connect LLMs with permissioned data. We:
- Offer permissioned data connectors to various data sources and data formats (APIs, PDFs, docs, etc.) to hydrate your Vector DB with permissioned data from GDrive, Slack, Confluence, Salesforce and 100+ SaaS sources
- Expose a simple UI and high level API that allows any employee to quickly create a RAG application like a HR Chatbot that takes a user’s query, automatically fetches the relevant data and securely feeds it to an LLM
- Expose a granular, low level API, that allows developers to take full control over chunking, embedding, search, prompting and more
MongoDB as the Datastore
Although the Vector DB market is still young, MongoDB Atlas' established position in the market offers developers the ability to get to market fast with minimal cost and complexity. MongoDB Atlas unified query API provides control needed to define powerful Foundation Model prompts by combining vector search with other query capabilities available in MongoDB (text search, geo-spatial search, etc.), providing extremely flexible and powerful ways of defining additional filters on vector-based queries to improve accuracy and reduce hallucinations of LLMs. Moreover, as an established player in the market, MongoDB Atlas helps Enterprises achieve enterprise-ready performance, scale, and security while still being on the bleeding edge of AI adoption.
MongoDB Atlas
MongoDB offers a free forever Atlas cluster in the public cloud service of your choice. This can be accomplished very quickly by following this tutorial or you can get started directly here.
The workflow
- Point Credal to your MongoDB instance
- Load the documents into a collection through the UI or APIs
- Connect the collection to an LLM, and set custom prompts and tools
- Deploy your POC and collect feedback from users
- Customize your parsing, chunking, embedding, and retrieval strategy
- Observe, monitor, and improve over time
Point Credal to your MongoDB instance
Credal knows how to interact with MongoDB Atlas out of the box - simply connect your cluster. Credal supports major auth schemes like X.509.

Load the documents into a collection through the UI or APIs
Loading data from GDrive, Slack, or Confluence into your vector database is extremely easy, whether you choose to do it via the UI, or via the APIs.
Via the UI: First Connect your GDrive, Slack, or Confluence
GDrive: Google Drive can be connected to start creating permissioned RAG applications, using either OAuth - which allows users to select individual documents, folders and drives to connect to Credal, Domain Wide Delegation - which allows Credal to sync all your GDrive data in the background
When using OAuth, a user connects a specific document by simply pasting the URL into the Credal omnibox:
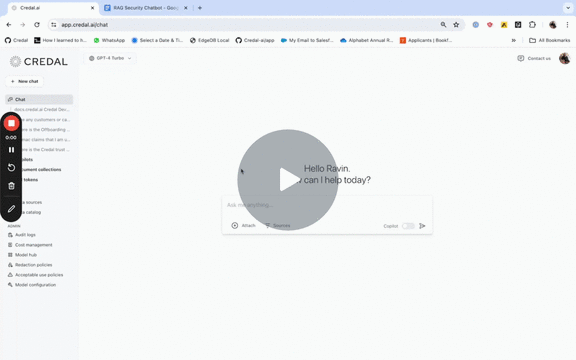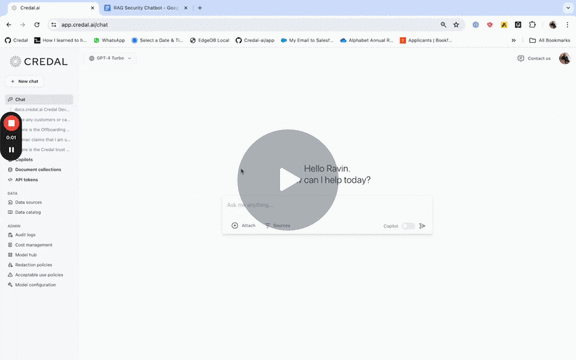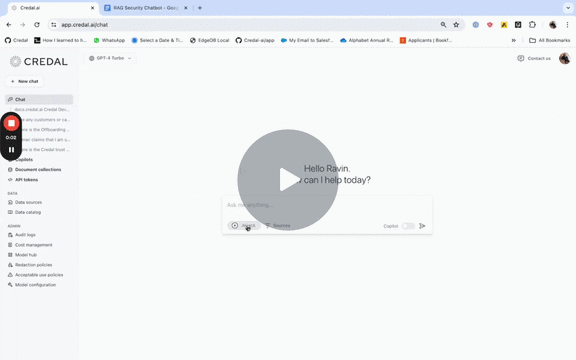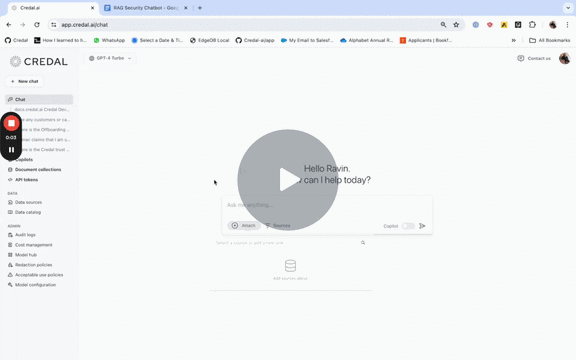
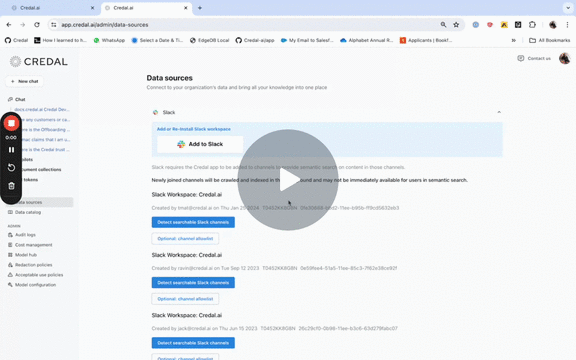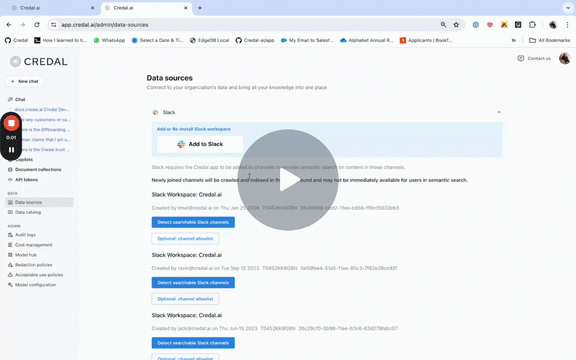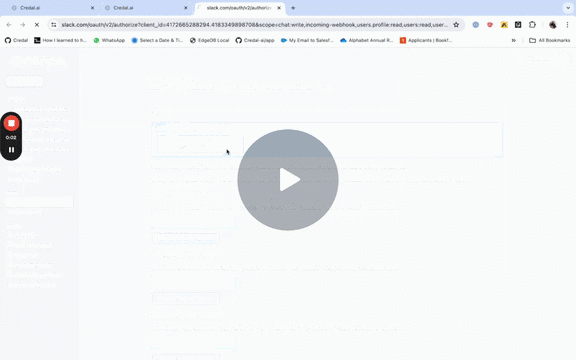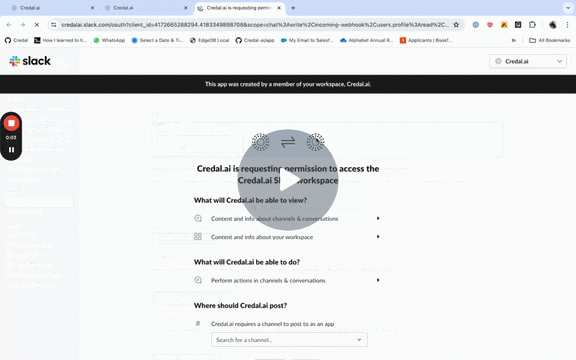
To add Slack, a Slack admin goes through a 1 minute Slack approvable process from the Credal Data Sources Configuration page (available to admins only), after which, they can add any and all Slack channels as needed.
Additional sources like Confluence, JIRA and Salesforce can be added by simply adding an API key for those tools.
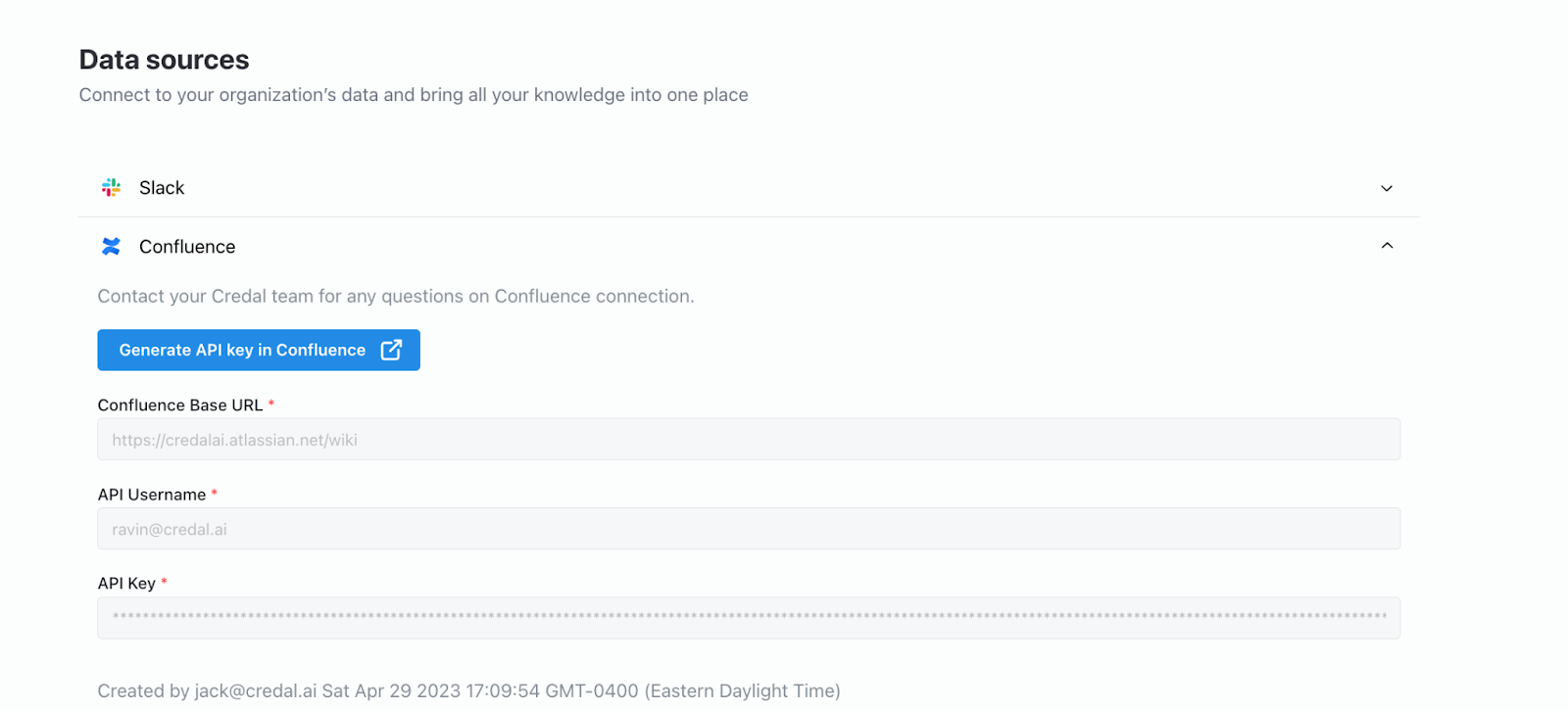
Once the API key is added, after a short delay while Credal syncs the data, the resources from those tools will appear in the search dropdown. If you want to manage the upload process yourself, adding data through the Credal APIs is also really simple, and works through our upload-document-contents endpoint. Send us a request with the document name, contents, allowed users, and an external id (i.e. the ID from the source system from which the doc came, if it has one), along with any other metadata you want to store in your MongoDB.

Credal will automatically handle the chunking and parsing for now (although we’ll see in a second how you can take control of that as you get into more complex use cases with need for finer grained control).
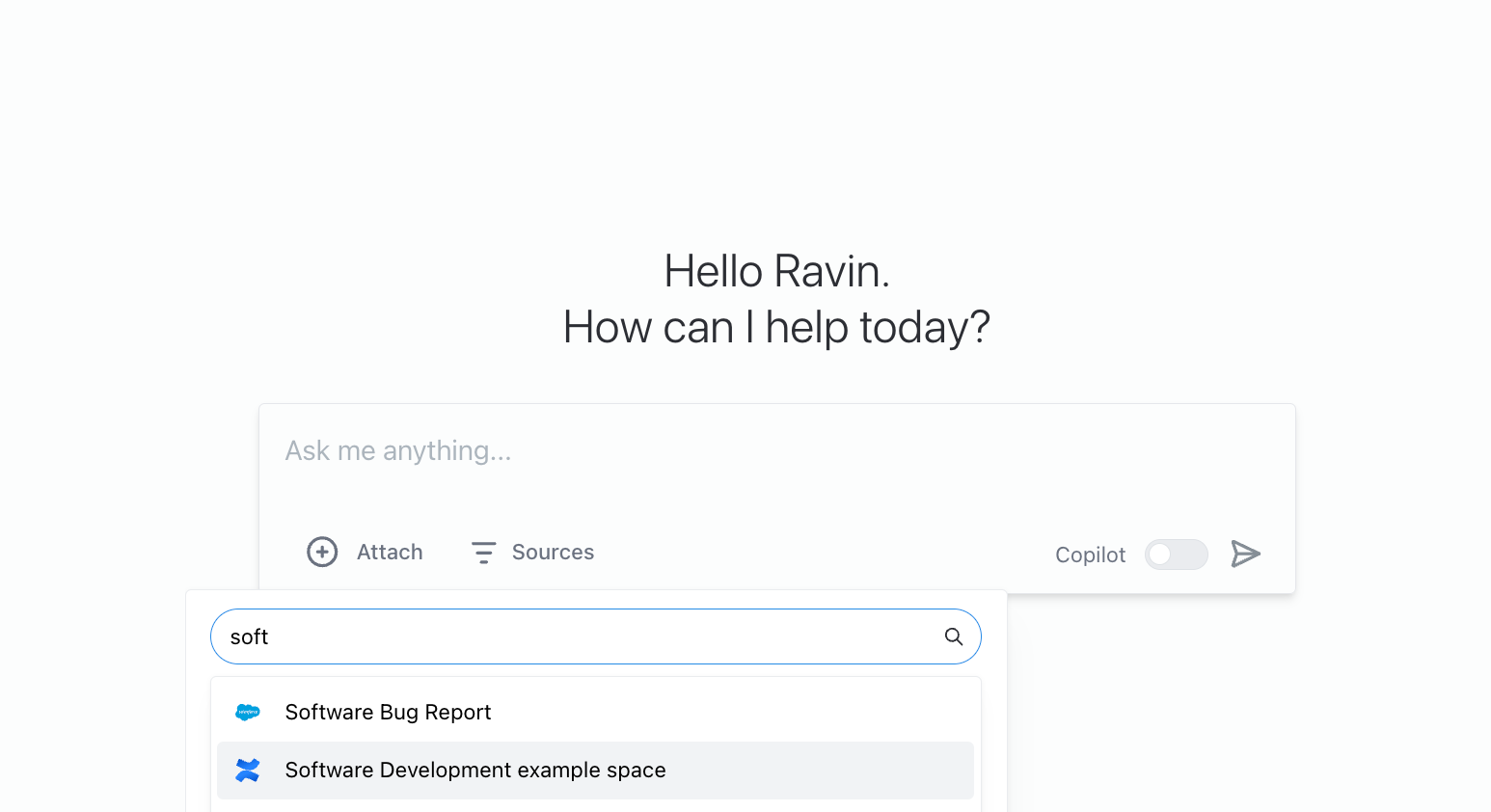
Connect the data to an LLM, and set custom prompts and tools
As soon as the data is connected, it is available for use in a chat with an LLM. However, enterprises often want to create curated workflow assistants that can be used to search through specific subsets of data, such as the HR benefits documentation, or the company IT policies, or Sales collateral and FAQs, etc.
Often these may need special, custom prompts. The video below shows adjusting the default model to Claude 3 Opus, as well as making some minor edits to the prompt fed to the LLM to automatically inject any details we may have about the end user from the Enterprise HRIs, as well as a few simple wording changes.
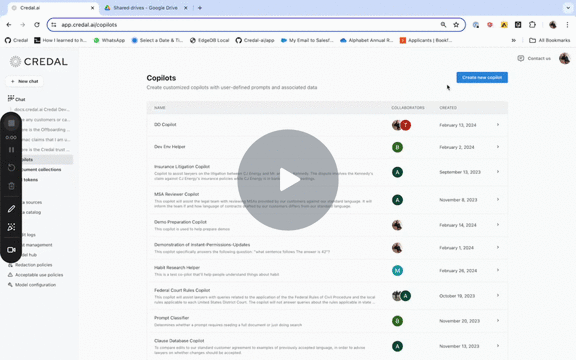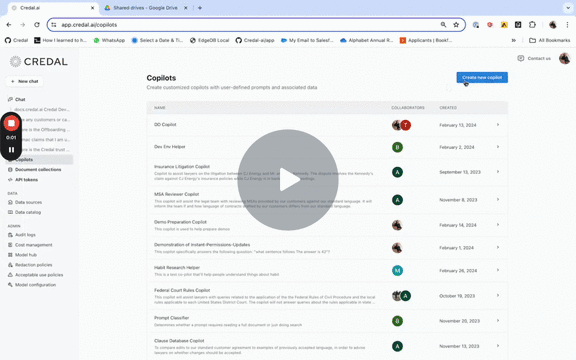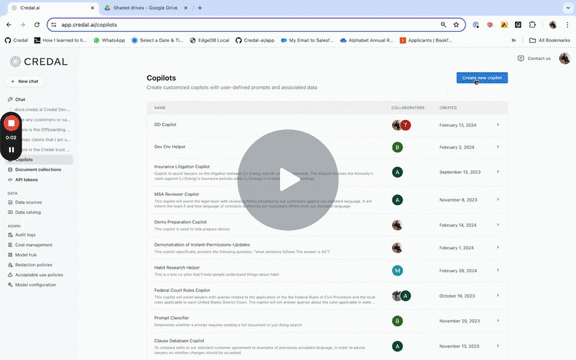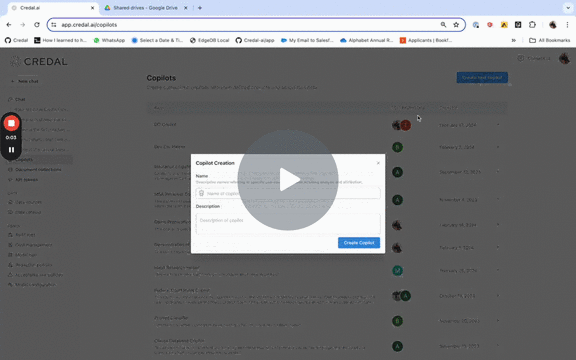
As usual, data can be connected by pasting the URL, or searching for and selecting the relevant data from the drop down.
Deploy your POC and get feedback from Users
Deploying a POC with Credal is as simple as two clicks:
- Click the Deploy Tab
- Click the button
Customize your parsing, chunking embedding and retrieval strategy with MongoDB
Get the best of both worlds with the customization and control you need to optimize your applications, with Credal’s out of the box functionality.
Credal’s parsing and chunking pipeline respects the nuanced formats of different data sources. When you want more control, you can easily override Credal’s builtins. Credal supports webhooks to delegate chunking to your custom code - simply wrap your logic in an API endpoint that interprets Credal’s parsing spec and drop your endpoint into Credal.
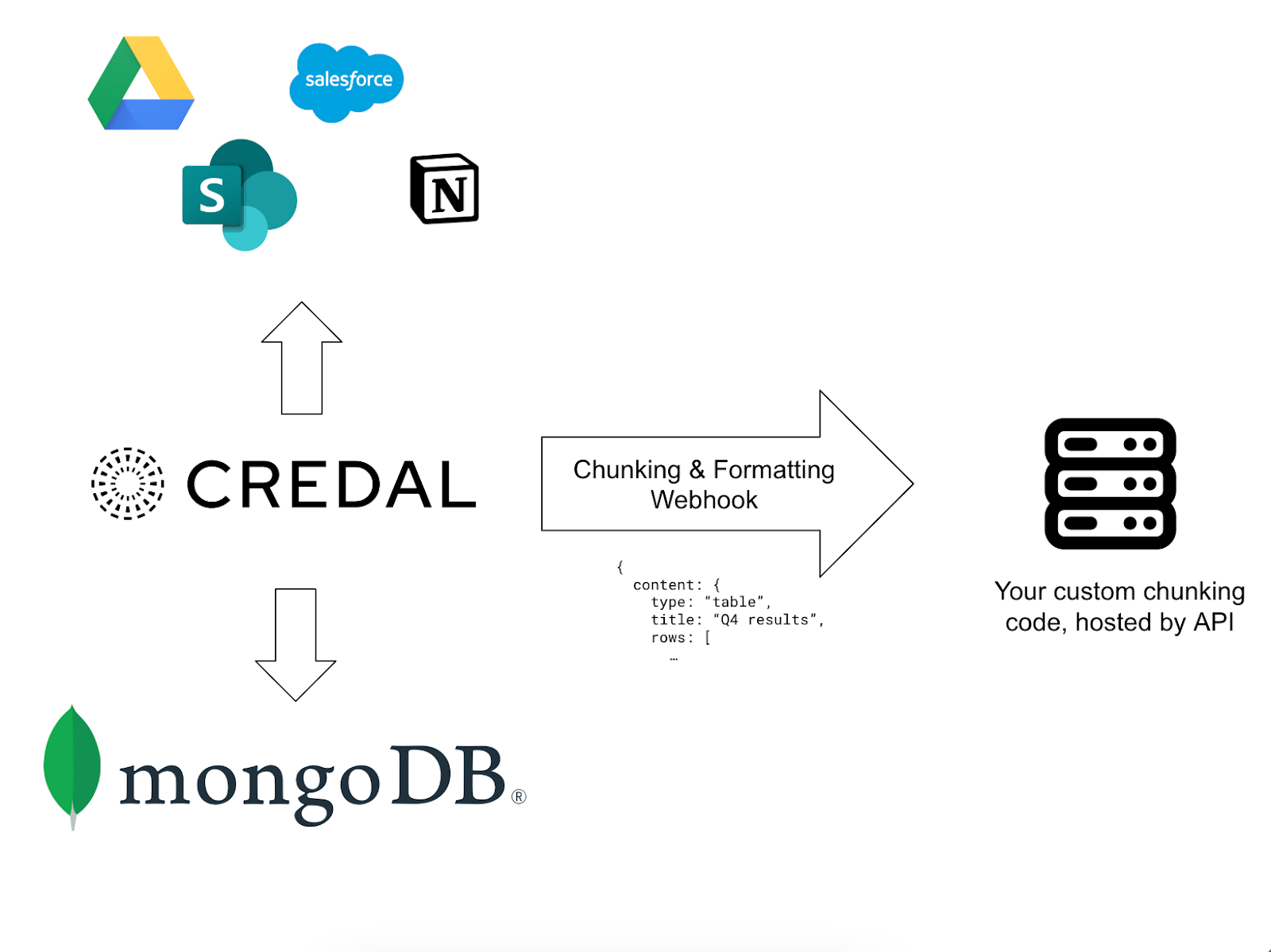
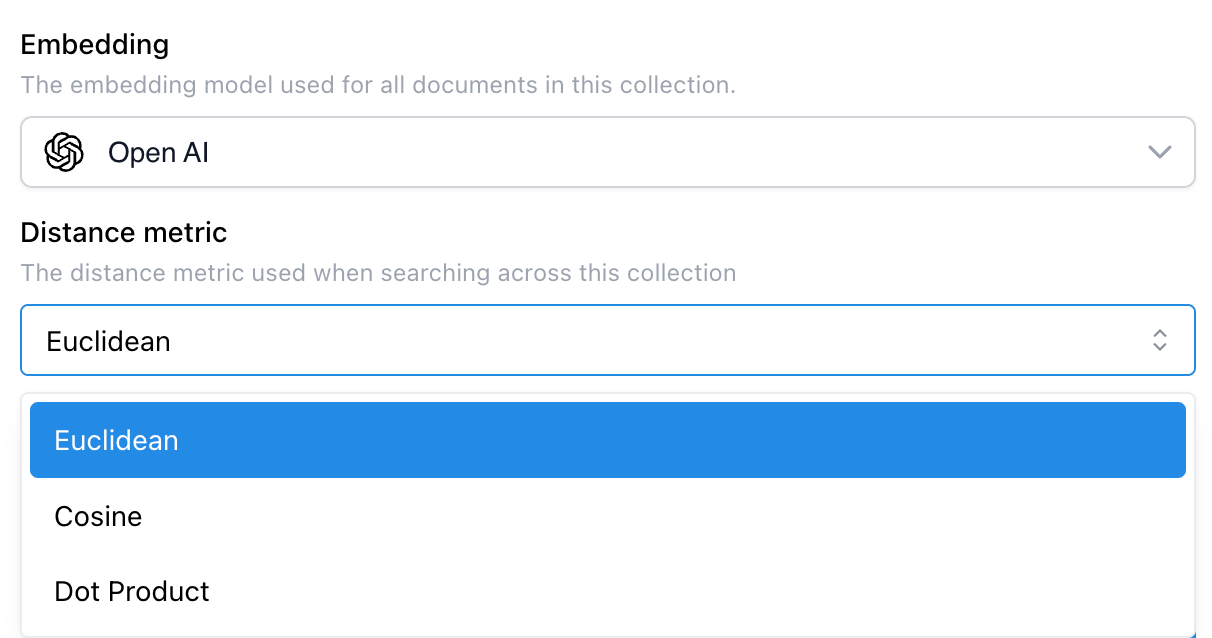
As always, Credal takes care of the data pipeline including crawling sources, interpreting source formats and permissions systems, retrying errors, etc. Easily customize embeddings model and experiment with new embedding model releases from all major providers per-collection, without disrupting your production workloads.
Ship and Iterate!
In this guide, we’ve walked through the process of building a RAG application in Credal powered by your existing MonogDB Atlas instance. This lets you stand up a simple RAG application in minutes, while still retaining absolute control over every part of your application: chunking, parsing, embedding, retrieval, and generation. Credal provides you Enterprise grade security and real time permissions guarantees synced from your source systems out of the box, and MongoDB gives you the power of an Enterprise ready Vector Search with a highly flexible document model that can meet the scale, security, and performance users expect.
Want to learn more?
Have questions on the above or want to know how these apply more specifically to your needs? We’re happy to chat. Drop us a line at sales@credal.ai!


