
Our customers ship thousands of agent runs every day, but we had no reliable way to tell which ones were good. “Good” means something specific: did the agent finish the task, did it use tools sensibly, did it waste calls, did it loop. We had no structured way to evaluate the tool calls inside a trajectory, and we didn't have any understanding of why tool call quality was the way it was.
We wanted to enforce human plus LLM labeling on every trajectory. We built a council (Claude, GPT-4o, and Gemini in stage 1, with an Opus chairman issuing the final session-level call) and ran it over the same set of trajectories our human raters were labeling. The hope was that if the council and humans agreed, we could mostly retire the human pass.
The first alignment check between LLM Council and human evaluation ended up. agreeing on roughly 60% of slots overall, and on the field that matters most for product decisions, “did the agent use tools appropriately,” they only agreed about half the time. 60% is not shippable as a replacement for human labelers, but it's also not low enough to walk away from. It's low enough that we had to figure out why.
So instead of asking “is the council right?” we pondered if “when the council and humans disagree, what is the structure of the disagreement, and which side is closer to the truth?” Disagreements weren't random noise. They were systematic, field-specific, and almost always traceable to a rubric ambiguity, a severity-threshold mismatch, or a known failure mode of one of the two raters. Once you can name the failure mode, you can write a rule for it. Once you have rules, you can scale adjudication.
Setup: 450 sessions, four dimensions task_completed, efficiency_bucket, tool_policy, looped, labeled independently by both the council and human raters.
The aggregate 66.6% number on its own doesn’t tell us the big picture. It averages over fields with very different difficulty (everyone agrees on looped, few agree on tool_policy) and hides which side was wrong when they disagreed.
Before any reconciliation, here is how often the council's session-level label exactly matched the human's, field by field:
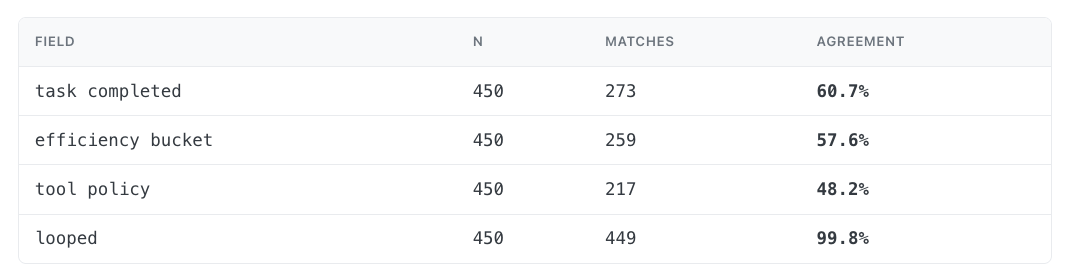
Table 1 — First go at council ↔ human agreement, per field, before any reconciliation.
Every time we adjudicated a disagreement we tagged it with one of four causes:
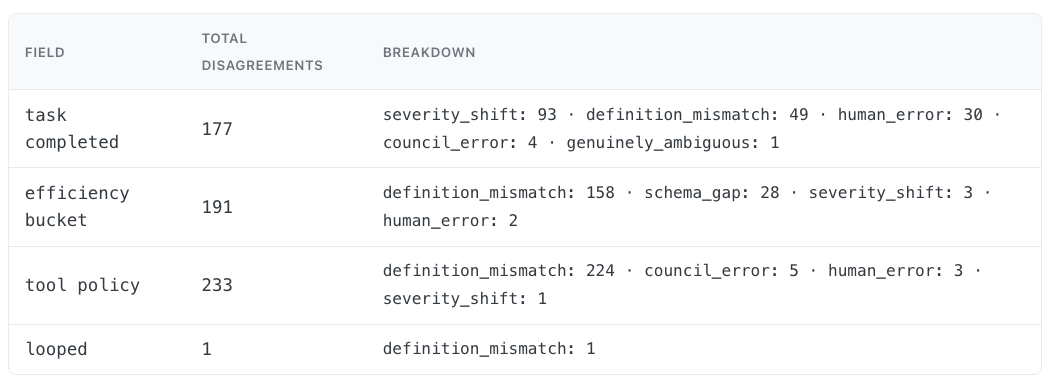
Table 2 — Disagreement causes per field, across all reconciled sessions (61 human-adjudicated + 280 AI-adjudicated).
We manually adjudicated 61 sessions to derive explicit reconciliation rules, then applied an AI:
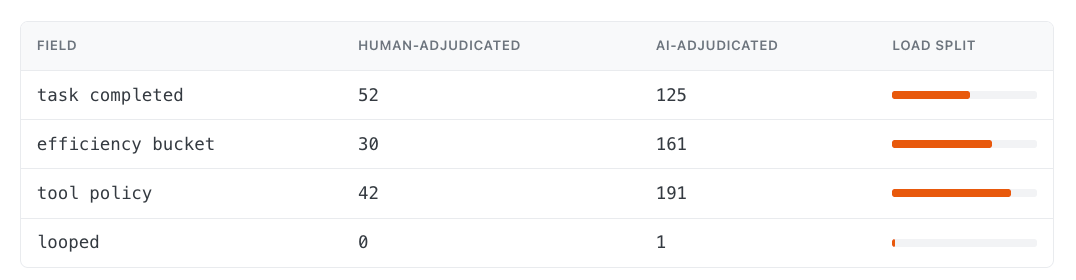
Table 3 — Bars show AI-adjudicated load per field.
Human labelers handled the first ~60 sessions to define the rules. The AI adjudicator applied them across the rest.
The important sanity check: when the AI broke a tie, did it side with the rubric we'd encoded for that field? It did, and the per-field skew is sharper than I expected.
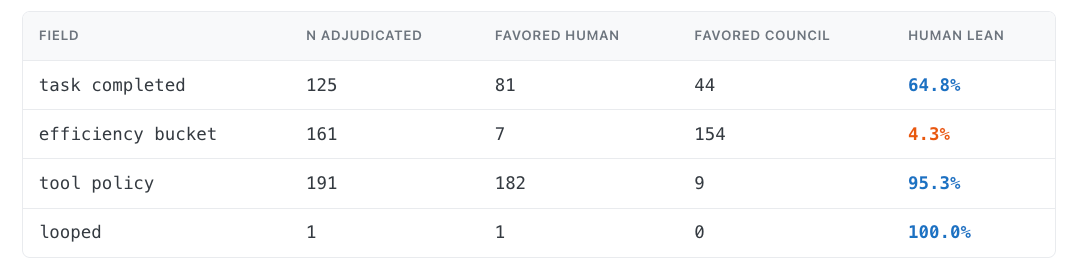
Table 4 — On every disagreement the AI adjudicated, which side did it choose?
This table is checking whether the AI adjudicator followed the rules we gave it. For each field, we looked at the cases where humans and the council disagreed, then counted whether the AI chose the human label or the council label.
The rules were field-specific because the two raters had different failure reasonings:
The final test is whether the calibrated dataset (agreement-where-they-agreed, adjudicated-where-they-didn't) is meaningfully closer to ground-truth human labels than the raw council output.
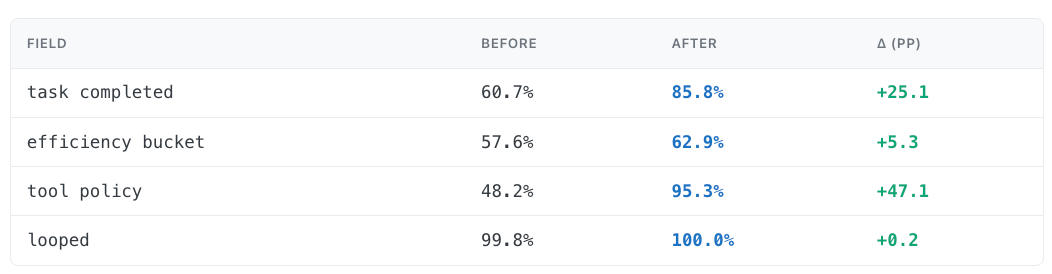
Table 5 — Calibrated label vs human reference, before and after reconciliation.
efficiency_bucket barely moves by comparison because the field is harder to reconcile with a single final label: efficiency is continuous, task-difficulty dependent, and easy to disagree on at the boundary between efficient, slightly_over, and wasteful. In those cases the council often had the better per-call view, but choosing the council label does not necessarily make it match the original human label. It makes the calibrated label more defensible, not more human-like.
tool_policy moves from 48% to 95%. That's the field where the council's rubric was most miscalibrated, and it's also where the AI adjudicator leans hardest toward the human side. The council had a consistent bias: it often marked tool use as unnecessary when a human would say the tool call was a reasonable way to answer the user's request. Once we made that failure mode explicit, the adjudicator could correct it consistently.
The bigger lesson is methodological.You can't replace human judgment with an LLM council in one move, but you also don't have to choose between them. Treating their disagreements as data is what turns two raters into one reliable dataset.
Our findings are consistent with the broader calibration literature: raw LLM judgments are not automatically reliable measurement instruments. The council was useful, but its errors were field-specific and systematic, so we had to calibrate council labels against human adjudication before using them as training data.
Part two is about what we do with that dataset: training a multi-head encoder to predict per-tool-call quality, fitting a single trajectory-level Q-score, and using both to spot tool calling quality downgrade in production agent before our users.
If this type of problem is interesting to you, we're hiring: credal.ai/careers.
One platform for all agents. Full visibility for admins, full access for teams.
One platform for all agents.
Full visibility for admins, full access for teams.


