
AI Data security is a very common concern for enterprises trying to use AI models like ChatGPT, Claude, or Bard. Information security policies and data protection agreements and privacy policies vary, so as the number of tools using AI increases, preventing data security issues across these providers grows too. Within the overall question of AI security, data security is perhaps *the* most important problem. As AI algorithms become more fundamental to how businesses work, understanding the real data security threats becomes essential to successfully protecting a company's AI systems.
This guide is intended to help enterprise executives, cyber security professionals and ML and AI practitioners
There are essentially three different categories of data security threats that businesses have with regards to data security practices related to AI:
To begin understanding the risks associated with models learning business secrets and PII, it is helpful to understand the basic workings of these models. Large Language Models are typically trained in a two-step process: in the first step, they are fed a vast amount of text data, primarily from the internet. That allows them to infer statistical correlations that indicate what types of words, or sequences of words, are most likely to follow any given word or sequence of words. This means that if a model is provided sensitive information in its training, it may learn things that are not desirable for it to know. For example if given access to company documents with employee SSNs, it may learn from those documents that the sequence of words “John Smith’s SSN“, is statistically correlated with “725-30-2345” e.t.c. (Obviously, this is a made up example)
In the second step, often called ‘Fine Tuning’, the model is usually given prepared examples of inputs, with the desired output, and is taught to try and emulate the style of the input/output examples wherever possible. For example, a model may be given lots of examples of text which indicate a question formatted in a particular way (eg: “Q. How many days are there in a Leap Year?”), followed by an answer, also formatted in a predictable way (e.g. “A: 366”). That helps the model understand that when it sees a question formatted in that way, it ought to provide an answer with the right formatting and style. This sort of training is what helps transform the base model, which can be thought of as a simple “next best word predictor” into a more useful “instruction following” AI like Chat GPT. Similarly to with model training, if the fine tuning step includes examples of a user asking the question “What is the coca cola recipe?” and getting a factually correct response, it could learn that when asked “What is the coca cola recipe”, this is the correct response it should give.
After several incidents early this year where employees pasted company secrets into ChatGPT, there has been much talk about whether Generative AI models could learn these secrets, or memorize personally identifiable information (PII). Concerns focus on compliance with data privacy legislation like the EU GDPR, or California CCPA. In response to those concerns, OpenAI changed their data protection policies on March 1st, 2023 to say that data submitted through the API will not be used for model training. Data submitted in the ChatGPT UI can still be used for these purposes. When models are trained on this data, it's still unclear how quickly the models can “learn” these secrets or “memorize” PII or other unique identifiers. A research paper written by security experts like Nicolas Carlini at Google Deepmind and others, indicates that GPT 2 could memorize unique identifiers that it saw 33 times in its training data, but not if it saw it 17 times or less. For certain cases, a mere 10 total appearances appeared to be enough for the model to 'memorize' it. However, the research also indicated that models would be a lot better at doing this as they got bigger.


The tables above are taken from a 2021 research paper discussing the privacy implications of LLMs. The research showed that GPT-2, was able to memorize some unique ids from as little as 10 appearances, although 22 appearances were necessary before urls with PII were reliably memorized. Modern models are said to be 1000x more powerful than the model on which this research was conducted.
Today the biggest models like GPT 4 are said to have up to 1.7 Trillion parameters. That's 1000x bigger than the model studied in this paper. Research is still lacking on the ability of today's best models like GPT 4 to learn personally identifiable information, meaning that the implications for data privacy are still very unknown. Moreover, sending data to LLMs without the right data protection agreements in place can permit them to train models on that data *forever* , so the performance of today's model to memorize an SSN or learn a business secret may not be a good guide to the risks businesses are taking on in the future, as AI technology gets bigger, more powerful, and more capable of learning new information.
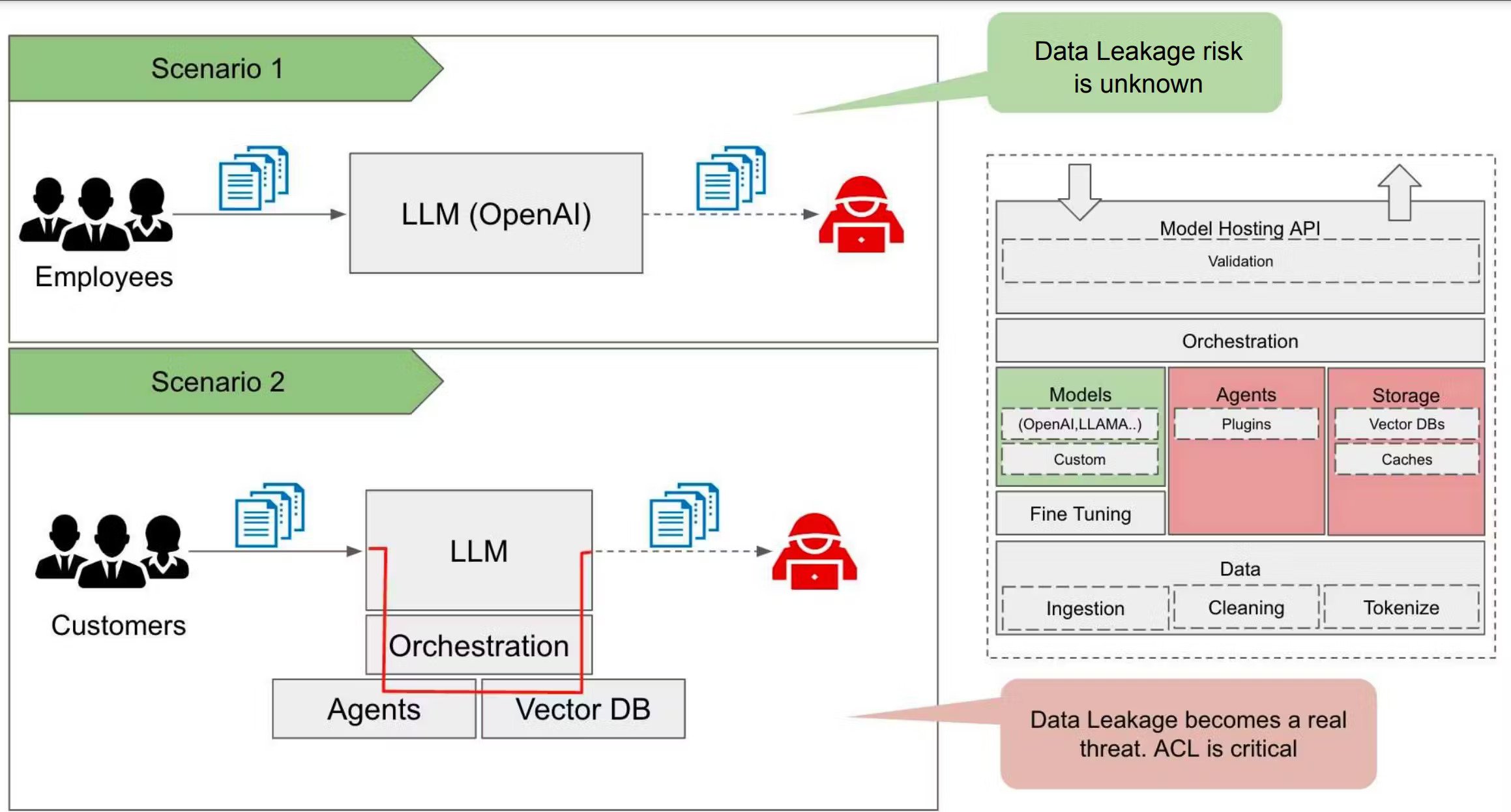
Today's models don't consider what information should be accessible to which users. This is probably the most important security problem for an enterprise to manage before using any LLM on company data. Since most language data at an enterprise exists in access controlled systems like SharePoint, OneDrive, O365, Google Drive, Slack, Notion, Box etc, connecting these data sources to an LLM risks removing those permissions.
Imagine an employee using an internal Chat GPT tool that's connected to a "Vector Database" (these are special databases that store data for use with AI models) containing data from your Google Drive, or Office 365.
In Office 365, the user has access to a document called “Company 2022 Financial Results”, but they do not have access to “Company 2023 Financial Projections”. If the user asks the question: “Summarize the key financial metrics for 2022 and 2023”, the model searches the connected data to find relevant documents to answer this question. Both documents are relevant, so the user gets a response summarizing the content of both documents. That answer may contain secrets about the company’s future financial projections, which they should never have been allowed to access.
To handle this, the vector database that the LLM retrieves from needs to mirror the permissions of the source systems from which the data is drawn. The LLM orchestration layer can then ensure that the query only retrieves context that the end user asking the question actually has permission to see.
Successfully implementing this involves solving several difficult engineering problems:
1. How do you handle automatically updating the permissions cache in real time?
2. How do you keep those permissions up to date with company's Single Sign On?
3. What happens when a user leaves an organization, and their documents are transferred to someone else?
4. When building custom AI applications for a specific purpose (such as the customer support bot), how do you create application tokens that can be permissioned to only a subset of the relevant data?
5. How do you automatically refresh the permissions cache across all applications?
6. When a user asks for data to be deleted under GDPR or data retention policies, how do you guarantee their personal data is actually removed from all relevant systems?
These are extremely challenging engineering problems without which there is no credible path to widespread AI adoption on internal corporate data, the vast majority of which has some level of access controls applied. As of today, the only solution on the market that credibly solves these problems across internal chat and custom built applications and externally procured tools is Credal.
So far, none of the major Large Language Model providers have been hacked. OpenAI did suffer a noteworthy information security incident which caused some customers' private data to be briefly visible to other customers. The incident was short lived (and blamed on a security bug in an open source software library called Redis, which they use).
As of yet, we know of no major breaches to data stored by Google Bard, Microsoft Azure Open AI or Anthropic, largely considered to be the key infrastructure providers for LLMs. AWS also have a newer AI infrastructure offering, called Bedrock.
Today, most of these providers will offer zero day retention policies in the data protection agreements they offer enterprise users (who are spending enough money with them), and so, with the right controls in place, the extent to which Open AI or Anthropic being hacked represents a significant increase in the overall threat surface area to a business is, we believe arguably quite analogous to the threat of any traditional software provider being hacked.
More risky than the foundation model providers themselves, are the large number of new AI tools cropping up in the AI industry, many of which are still very immature and lack the basic security practices that enterprises should insist on before handing over any data. This includes at a very minimum, SOC 2 Type 2 compliance, but more importantly from a security perspective, the usual requirements cyber security professionals would look for, such as rigorous regular penetration testing, 24/7 monitoring of event logs for suspicious activity and overall a mature approach to cybersecurity and data privacy.
For companies already in the Microsoft ecosystem who are particularly concerned about this, many are choosing to use Azure OpenAI, which provides the ability to run inference on OpenAI models, but fully hosted in Azure. Note that this is not technically in your Azure, but a centrally hosted Azure instance, but it does at least reduce the surface area of potential risk to just Azure. Whatever foundation model providers, infrastructure, and applications you choose to use and build in house, you’ll likely want to ensure that you use a provider like Credal.ai to ensure you get centralized visibility and control over what data each tool is accessing, and they are sending on to LLMs, all in one place.
In summary, the key data security risks to be aware of with AI models like ChatGPT and the best mitigations for each are:
The most fundamental security issue facing enterprises trying to deploy LLMs today is likely users being able to access documents they shouldn't through an AI system. The most fundamental compliance issue is likely the potential for models to memorize sensitive data or PII. Though current models may not perfectly memorize or retain sensitive data, this capability is likely to improve over time as models grow larger.
To discuss the AI data security risk guide and its implications for your business, book a conversation here
Credal gives you everything you need to supercharge your business using generative AI, securely.
